
Transformer:所有 LLM 的始祖,迈向 NLP 新时代的基础架构
论文名称:《Attention is all you need》
发布时间:2017/06/12
发布单位:Google、多伦多大学
小学生概括:传统的序列转换模型使用复杂的循环(RNN)或卷积 (CNN)神经网络,包括编码器和解码器。表现最好的模型会透过注意力机制连接编码器和解码器。
而我们提出了一种新的简单网络结构,Transformer,完全基于注意力机制,不再使用循环和卷积。
Transformer 的特别之处在于它用了一种叫"注意力"的方法来理解语言。这就像人类在读一个句子时,会特别注意某些重要的词一样。
在Transformer出现之前,人工智能处理语言时需要按顺序一个词一个词地读,就像我们从左到右读一句话。但Transformer可以同时看整个句子,这让它更快、更聪明。
论文链接:https://arxiv.org/pdf/1706.03762.pdf
核心技术:模型架构
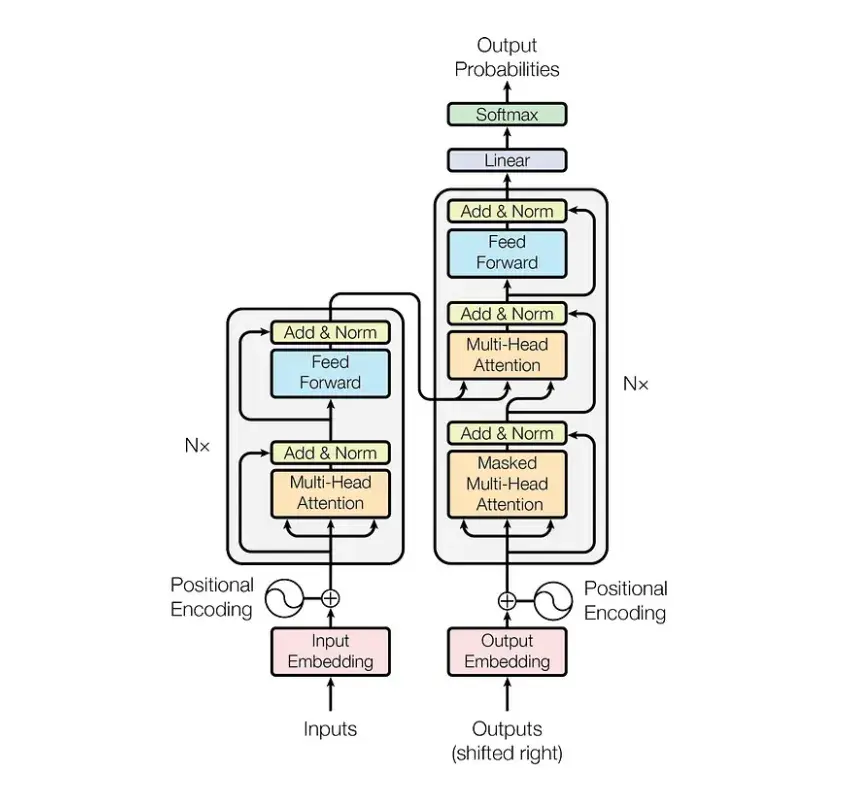
GPT-1:autoregreesive Transformer 始祖
论文名称:《Improving language understanding by generative pre-training》
发布时间:2018/06/11
发布单位:OpenAI
阅读重点:多层Transformer解码器、自回归模型
小学生概括:想象一下,你正在学习一门新的外语。一开始,你可能会通过大量阅读和听这门语言来熟悉它的结构和用法,这就像论文中说的"生成式预训练"。
在这个阶段,电脑会"阅读"大量的文本,学习语言的基本规则和模式。这就像你在学习新语言时,先大量接触这门语言,了解它的基本结构和常用表达。
接下来,当你想要完成特定的任务时,比如回答问题或写作文,你会针对这些任务进行专门的练习。论文中称这个过程为"判别式微调"。对电脑来说,这就是在完成特定的语言任务时进行额外的训练。
研究人员发现,先让电脑进行大量的"阅读"(预训练),再针对特定任务进行专门训练(微调),效果比直接让电脑学习特定任务要好得多。这就像你先广泛接触一门语言,再专门练习某项技能(如写作或口语),会比直接上手练习特定技能效果更好。
这种方法在很多语言理解任务中都表现出色,比如理解故事情节、回答问题,以及判断句子之间的关系等。研究人员发现,使用这种方法训练出来的通用模型,在多数任务中都比专门为单个任务设计的模型表现得更好。
总的来说,这项研究为让电脑更好地理解和使用人类语言开辟了新的道路,这对于改进各种语言相关的技术,如翻译软件、智能助手等都有重要意义。
链接论文:https://arxiv.org/pdf/1810.03993.pdf
核心技术:有监督微调架构
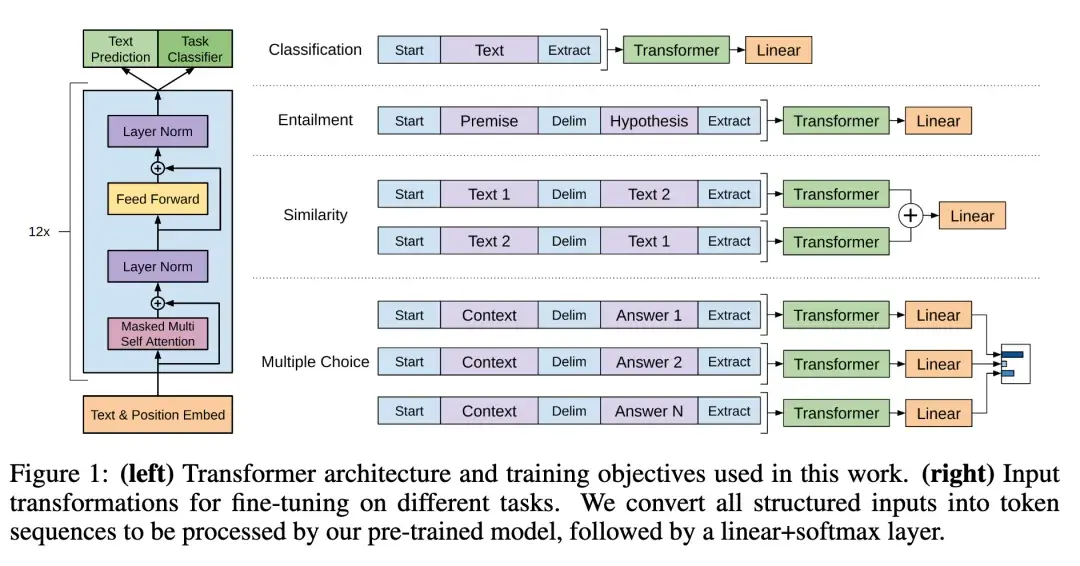
BERT:autoencoding Transformer 始祖,迈向 NLP fine-tuning 时代
论文名称:《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
发布时间:2018/10/11
发布单位:Google
阅读重点:自动编码模型、屏蔽标记和下一句预测。
小学生概括:想象一下,你正在学习一门新的语言。通常情况下,你可能会通过阅读课本,听老师讲解,然后做练习来学习。但是,如果有一种超级厉害的学习方法,可以让你更快更好地掌握这门语言,那会怎么样呢?
BERT就像是这样一个"超级学习机器"。它的特别之处在于:
- 广泛阅读: BERT会"阅读"大量的文章和书籍,就像一个贪婪的读书人一样。
- 上下文理解: 当BERT看到一个词时,它不只是理解这个词本身,而是会看这个词前后的其他词。这就像你在理解一句话时,不只看一个字,而是看整句话一样。
- 猜词游戏: BERT会玩一种特殊的"猜词游戏"。它会遮住一些词,然后根据周围的词来猜测被遮住的词是什么。这个游戏帮助BERT更好地理解语言。
- 预测下一句: BERT还会玩另一个游戏,就是猜两个句子是不是本来就应该挨在一起的。这帮助BERT理解更长的文章结构。
- 灵活应用: 经过这些"训练"后,BERT就变得非常聪明了。它可以快速地适应各种语言任务,比如回答问题、判断句子之间的关系等。
总的来说,BERT就像一个超级学霸,它通过大量阅读和特殊的学习方法,成为了一个在语言理解方面非常厉害的"机器人"。科学家们可以利用BERT来做很多有趣的事情,比如制作更智能的聊天机器人,或者帮助计算机更好地理解人类的语言。
链接论文:https://arxiv.org/pdf/1810.04805.pdf
核心技术:基于无监督特征的方法

Transformer-XL:让 Transformer 可以吃更长的句子
论文名称:《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》
发布时间:2019/01/09
发布单位:Google、卡内基麦隆大学
阅读重点:上下文分片、段级递归机制、相对位置嵌入
小学生概括:想象一下,你正在阅读一本很长的小说。传统的人工智能模型就像一个只能记住最后几页内容的读者,很容易忘记前面发生的事情。但是 Transformer-XL 就像一个超级厉害的读者,它能够:
分段阅读: 就像你可能会把一本长小说分成几个章节来读一样,Transformer-XL 把长文本分成小块来处理。这样它就不会因为文本太长而"晕头转向"。
记住重要信息: 当你读完一个章节,开始读下一个章节时,你会记住前面章节的重要内容,对吧?Transformer-XL 也是这样。它在处理每个新的文本块时,都会"回忆"之前块的重要信息,这样就能理解整个故事的上下文。
理解单词的位置关系: 在一个句子里,单词的位置很重要,对吧?比如"猫追狗"和"狗追猫"意思就不一样。Transformer-XL 有一种特殊方法来理解单词之间的位置关系,即使这些单词在不同的文本块里。
更快更好地理解长文本: 因为有了这些新方法,Transformer-XL 可以比以前的模型更快、更好地理解很长的文章,甚至可以写出连贯的长故事。
总的来说,Transformer-XL就像是给了人工智能一个超级记忆力和理解力,让它能像人类一样更好地理解和创作长文本。这对于未来的智能写作、自动翻译,甚至是创作小说都有很大的帮助!
链接论文:https://arxiv.org/pdf/1901.02860.pdf
核心技术:带状态重用的片段级递归

GPT-2:不想 fine-tune,我想要一个通用模型所有任务直接 zero-shot
论文名称:《Language models are unsupervised multitask learners》
发布时间:2019/02/24
发布单位:OpenAI
阅读重点:multi-task pre-training、模型到底是达到generalization还是memorization
小学生概括:想象一下,你有一个超级聪明的朋友。这个朋友从小就特别爱看书,各种各样的书都看。慢慢地,他变得无所不知。有一天,你突然问他一道数学题,虽然他从来没学过这道题,但他居然能回答出来!不仅如此,无论你问他什么问题 - 历史、地理、文学,甚至是你刚编的故事里的问题,他都能回答得头头是道。
这篇论文说的就是这样一个"超级聪明的朋友",只不过这个朋友是一个计算机程序,叫做GPT-2。科学家们让GPT-2"阅读"了海量的网页内容,相当于让它学习了人类在互联网上分享的大量知识。通过这种方式,GPT-2学会了理解和使用人类语言,而且能够应对各种不同类型的语言任务。
最神奇的是,GPT-2并没有为每个具体的任务专门学习。它就像是通过大量阅读获得了举一反三的能力,面对新问题时也能给出不错的回答。这让科学家们很兴奋,因为这意味着我们可能不需要为每个语言任务单独训练程序,而是可以创造出真正"通用"的语言理解系统。
这种方法就像是教会了电脑如何学习和思考,而不仅仅是记忆答案。这可能会让未来的人工智能变得更加智能和灵活,能够像人类一样应对各种新问题和情况。
论文链接:https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
核心技术:语言模型是无监督的多任务学习者

ERNIE:把知识图谱一起整合在 BERT 上
论文名称:《ERNIE: Enhanced Language Representation with Informative Entities》
发布时间:2019/05/17
发布单位:北京清华大学、华为
阅读重点:结构化知识编码、异构信息融合、知识编码器
小学生摘要:神经语言表征模型,例如在大规模文本语料库上预先训练的 BERT,能够从纯文本中捕捉丰富的语义模式,并进行微调以持续提升各种自然语言处理任务的性能。
但是现有的预训练语言模型很少考虑将知识图谱(KGs)纳入其中,而KGs可以提供丰富的结构化知识事实,有助于更好地理解语言。
我们认为KGs中的讯息性实体可以增强语言表征的外部知识。所以我们同时利用大规模文本语料库和知识图谱来训练一个增强语言表示模型(ERNIE),它能同时充分利用词汇、句法和知识讯息。实验结果表明,ERNIE在各种知识驱动任务上取得了显著的改善,同时在其他常见的自然语言处理任务上与最先进的模型BERT相当。
链接论文:https://arxiv.org/pdf/1905.07129.pdf
核心技术:提出了具有信息实体的增强语言表示(ERNIE),该模型在大规模文本语料库和知识图谱上预训练了语言表示模型

DistilBERT:利用知识蒸馏训练更小的 BERT
论文名称:《DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter》
发布时间:2019/10/02
发布单位:Hugging Face
阅读重点:Teacher-Student的架构、distillation loss
小学生概括:想象一下,我们有一个超级聪明的机器人老师,它懂得很多人类语言的知识。但是这个机器人太大了,需要很多电脑才能运行。现在,科学家们想要创造一个更小的机器人学生,它可以学习大机器人的知识,但是体积更小,运行更快。
这个过程就像是老师教学生一样。大机器人(老师)会教小机器人(学生)它所知道的一切。科学家们使用了一种叫做"知识蒸馏"的方法,就像把知识煮沸,然后把最精华的部分提取出来给小机器人学习。
在这个学习过程中,小机器人要完成三个任务:
- 理解人类的语言
- 学习大机器人的知识
- 尽量保持自己的想法和大机器人相似
通过这种方法,科学家们成功地创造出了一个叫做DistilBERT的小机器人。它只有大机器人(BERT)60%的大小,但是能够完成97%的语言理解任务,而且速度快了60%!
这项技术的意义在于,我们可以把这些聪明的小机器人放在手机或者平板电脑里,让它们帮助我们更好地理解和使用语言,比如翻译、写作或者回答问题。这样,每个人都可以随时随地使用先进的人工智能技术啦!
链接论文:https://arxiv.org/pdf/1910.01108.pdf
核心技术: 预训练语言模型。

T5:把 NLU 和 NLG 全部都当成 seq 2 seq 任务来训练吧
论文名称:《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》
发布时间:2019/10/23
发布单位:Google
阅读重点:input and output format、架构比较、预训练任务目标、ensemble效果比较
小学生摘要:让我们想象一下计算机是如何理解和使用人类语言的。这篇论文提出了一个有趣的想法:无论我们想让计算机做什么样的语言任务,都可以看作是"阅读一段文字,然后写出另一段文字"。
举个例子:
- 如果我们想让计算机翻译,我们可以给它一段中文,让它写出对应的英文。
- 如果我们想让计算机回答问题,我们可以给它一篇文章和一个问题,让它写出答案。
- 如果我们想让计算机总结文章,我们可以给它一篇长文,让它写出简短的概括。
研究人员发现,如果我们用这种统一的方式来训练计算机,它就能更好地学习语言的规律。就像人类学习一样,计算机先在大量文本上"预习",学会基本的语言知识,然后再针对特定任务"复习",这样就能在各种语言任务上表现得更好。
这种方法的好处是,计算机可以把在一个任务中学到的知识,用到其他任务中去。比如,它在学习翻译时掌握的语言知识,可能对回答问题或总结文章也有帮助。
通过这种创新的方法,研究人员让计算机在多项语言任务上都取得了很好的成绩,为未来的人工智能语言处理开辟了新的道路。
链接论文:https://arxiv.org/pdf/1910.10683.pdf
核心技术:对待每一个文本处理问题作为一个"文本的文字"问题,即把文字输入和生产新的文本作为输出。
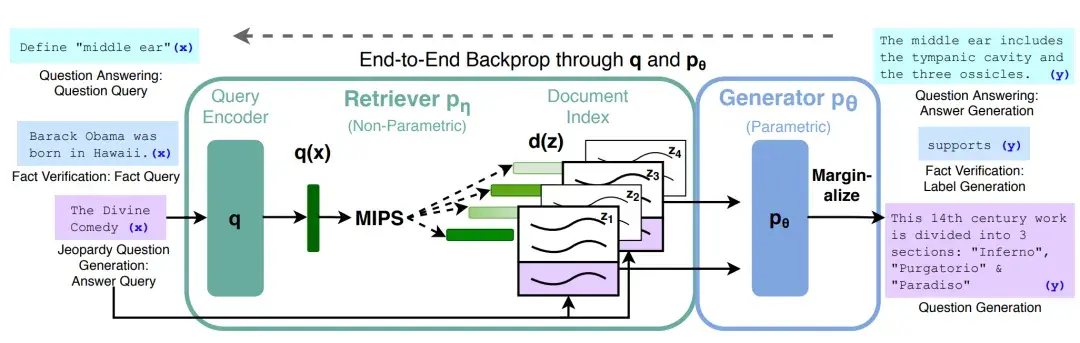
Retrieval-Augmented Generation (RAG):结合资料库检索,让 LLM 变得更强、回答讯息更正确
论文名称:《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》
发布时间:2020/05/22
发布单位:Facebook(Meta)、伦敦大学学院、纽约大学
阅读重点:RAG-序列和RAG-token模型,检索器和生成器架构
小学生摘要:想象一下,你正在为一场重要的考试做准备。你有两种方式来回答问题:
- 凭自己的记忆 (就像大型语言模型储存的知识)
- 查阅参考书(就像外部知识库)
RAG方法就像是把这两种方式结合起来:
- 首先,你会快速浏览一下参考书,找到可能有帮助的信息(这就是"检索"部分)
- 然后,你会结合参考书上找到的信息和你自己的知识,来组织一个完整的答案(这就是"生成"部分)
这样做有几个好处:
- 你可以获得最新、最准确的信息
- 你可以回答一些仅凭记忆可能答不上来的问题
- 你的回答会更加详细和准确
总的来说,RAG就像是给了计算机一个"智能助手",帮它在回答问题时既能利用自己的"大脑",又能查阅"参考书",从而给出更好的回答。
链接论文:https://arxiv.org/pdf/2005.11401.pdf
核心方法:联合“预训练的检索器(查询编码器+文档索引)”+“预训练的 seq2seq 模型(生成器)”+“微调”端到端
GPT-3:别再玩 fine-tune 了,in-context learning 和钱才是王道
论文名称:《Language Models are Few-Shot Learners》
发布时间:2020/05/28
发布单位:OpenAI
阅读重点:limitations、不使用fine-tune原因、data contamination、in-context learning
小学生摘要:最近的研究表明,通过对大量文本进行预训练,然后在特定任务上进行微调,可以在许多自然语言处理任务和基准测试中取得显著进展。
尽管在架构上通常是通用任务的,但这种方法仍需要数千甚至数万个特定任务的微调数据集。相比之下,人类通常可以仅凭几个例子或简单的指令来完成新的语言任务,而当前的自然语言处理系统在这方面仍然存在很大挑战。
所以在这里,我们扩展语言模型,来大幅改善了通用任务、少量样本的性能,有时甚至达到了与先前最先进的微调方法相竞争的水平。
具体而言,我们训练了 GPT-3,其是一个自回归语言模型,具有1750亿参数,比之前的非稀疏语言模型多10倍,并在少样本情况下测试其性能。对于所有任务,GPT-3在没有任何梯度更新或微调的情况下应用,也就是任务和少量范例的情境,纯粹通过与模型的文本交互来指定。GPT-3在许多自然语言处理数据集上表现出色,包括翻译、问答和填空任务,以及一些需要即时推理或领域适应的任务,比如拼字、在句子中使用新词或进行3位数的算术运算。但是同时我们还发现了一些数据集,GPT-3的少样本学习仍然存在困难,以及一些 GPT-3面临与在大型 Web 文集上训练相关的方法问题。最后我们发现 GPT-3可以用来生成新闻文章样本,人类评估者很难将其与人写的文章区分。另外我们也讨论了这一发现和 GPT-3整体对社会的更广泛影响。
总的来说,GPT-3就像是一个超级学习能力强的AI同学,只需要少量的例子就能学会新知识,这种学习方式我们称为"少样本学习"。
链接论文:https://arxiv.org/pdf/2005.14165.pdf
核心技术:上下文学习

AutoPrompt:prompt 效果有时甚至比 fine-tune 好
论文名称:《AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts》
发布时间:2020/10/29
发布单位:加州大学尔湾分校、加州大学柏克莱分校
阅读重点:基于梯度的提示搜索、自动化标签标记选择
小学生摘要:让我们想象一下电脑是一个非常聪明的朋友,它通过阅读大量的文字学会了很多知识。现在,我们想知道这个朋友到底学会了什么。
以前,我们会直接问它问题,比如"你觉得这部电影好看吗?"但是有时候它不太明白我们的问题,回答得不太准确。
现在,科学家们发明了一个叫AutoPrompt的新方法。这个方法就像是帮我们设计更好的问题。它会自动尝试各种不同的问法,找出最能让电脑朋友理解并正确回答的方式。
有趣的是,用这种方法问出的问题,有时候比我们直接教电脑新知识还要有效!比如,在判断一句话是高兴还是伤心,或者理解两个句子之间的关系等任务上,AutoPrompt帮助电脑朋友表现得非常出色。
这个发现告诉我们,我们的电脑朋友其实已经学会了很多东西,关键是要用正确的方式去问它问题。将来,这种自动设计问题的方法可能会让我们更容易地了解和使用人工智能。
链接论文:https://arxiv.org/pdf/2010.15980.pdf
核心技术:将 AutoPrompt 应用于探测掩码语言模型(MLM)进行情感分析的能力
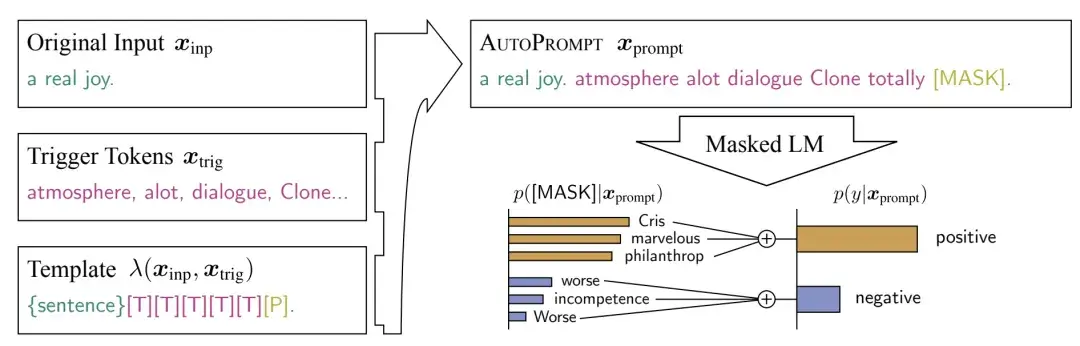
Rotary Position Embedding:目前在 LLM 上最普遍使用的 embedding 方式
论文名称:《RoFormer: Enhanced Transformer with Rotary Position Embedding》
发布时间:2021/04/20
发布单位:追一科技
阅读重点:旋转位置嵌入、长期衰减性质、线性自注意力
小学生摘要:想象你正在看一本很长的故事书。在这个故事中,每个字、每句话的位置都很重要,因为它们的顺序会影响整个故事的意思。现在,我们要教会电脑理解这个故事,就像你读懂它一样。
研究人员发明了一个聪明的方法,叫做"旋转位置嵌入"。这个方法就像给故事书的每一页都贴上一个特殊的标签,这个标签告诉电脑:
- 这一页在整本书中是第几页(绝对位置)
- 这一页和其他页之间的关系(相对位置)
有趣的是,这个标签是用"旋转"的方式来表示的。你可以想象每一页都在一个大圆盘上,根据它在书中的位置,圆盘会旋转到不同的角度。
这个方法有几个很棒的特点:
- 灵活性: 不管书有多厚(序列有多长),都可以轻松处理。
- 远近关系: 离得近的页面之间关系更紧密,离得远的关系就没那么密切了。这很符合我们读书时的感觉,对吧?
- 高效: 电脑可以更快地处理这些信息。
研究人员把这个方法用在了一种叫做Transformer的人工智能模型上,创造出了更强大的RoFormer。他们让RoFormer去理解很长的文章,结果发现它比其他方法都要好。
总的来说,这项研究帮助电脑更好地理解长文本,就像人类阅读长故事一样,能够把握整体结构,又能关注细节。这对于开发更智能的AI系统,比如能写作、回答问题的机器人来说,是一个很重要的进步。
链接论文:https://arxiv.org/pdf/2104.09864.pdf
核心技术:旋转位置嵌入(RoPE)
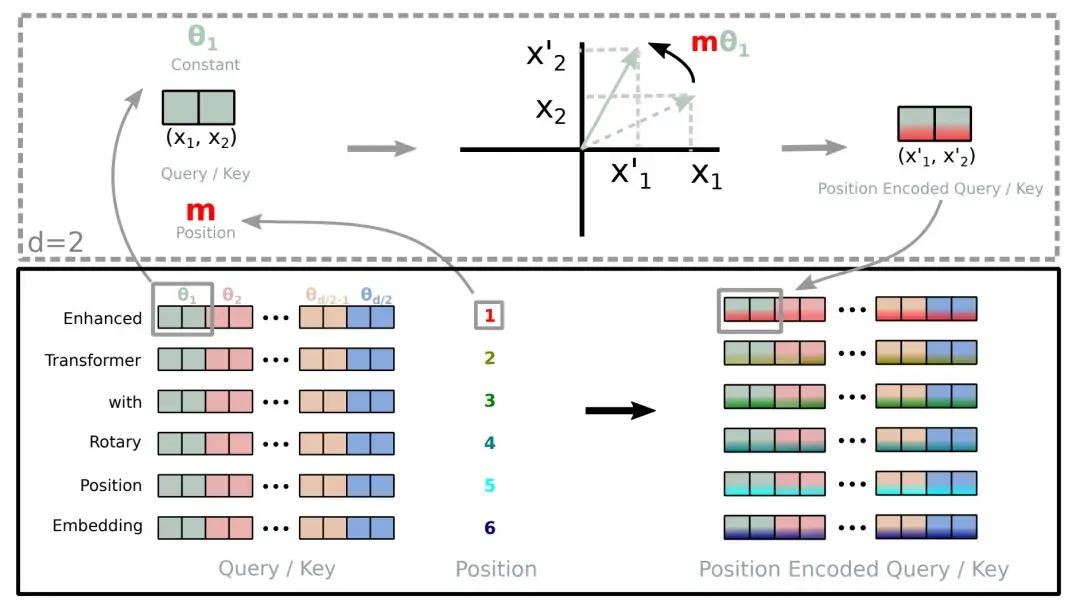
LoRA:Fine-tune 不了整个 LLM,那 fine-tune 一点点就好
论文名称:《LoRA: Low-Rank Adaptation of Large Language Models》
发布时间:2021/06/17
发布单位:Microsoft
阅读重点:低秩自适应、推理延迟和适配器问题、LoRA 应用到 Transformer、实际好处和局限性
小学生摘要:想象一下,你有一本超级厚的百科全书,里面包含了各种各样的知识。这就像是一个大型语言模型。
现在,你想要用这本百科全书来回答一些特定领域的问题,比如只关于历史的问题。一种方法是把整本书都重新写一遍,加入更多历史知识,但这样做太费时间和精力了。
科学家们想出了一个聪明的办法:不改变原书的内容,而是在每一页旁边贴上一些小便签。这些小便签上写着一些补充信息,帮助你更好地回答历史问题。
这个方法就像是LoRA(低秩适应)。它不改变原来的大语言模型(就像不改变百科全书的内容),而是添加一些小的、可以训练的部分(就像那些小便签)。这样做有很多好处:
- 省时省力:你不需要重写整本书,只需要写一些小便签。
- 节省空间:小便签比整本新书占用的空间要小得多。
- 快速切换:你可以轻松地换上不同主题的便签,让同一本书适应不同的需求。
- 效果好:虽然只是加了小便签,但在回答特定问题时,效果可能和重写整本书一样好,有时甚至更好。
这就是LoRA的核心思想:用聪明又省事的方法,让已有的大型AI模型更好地适应特定任务,而不需要每次都"重写整本书"。
链接论文:https://arxiv.org/pdf/2106.09685.pdf
**核心技术:**低秩适应(LoRA)
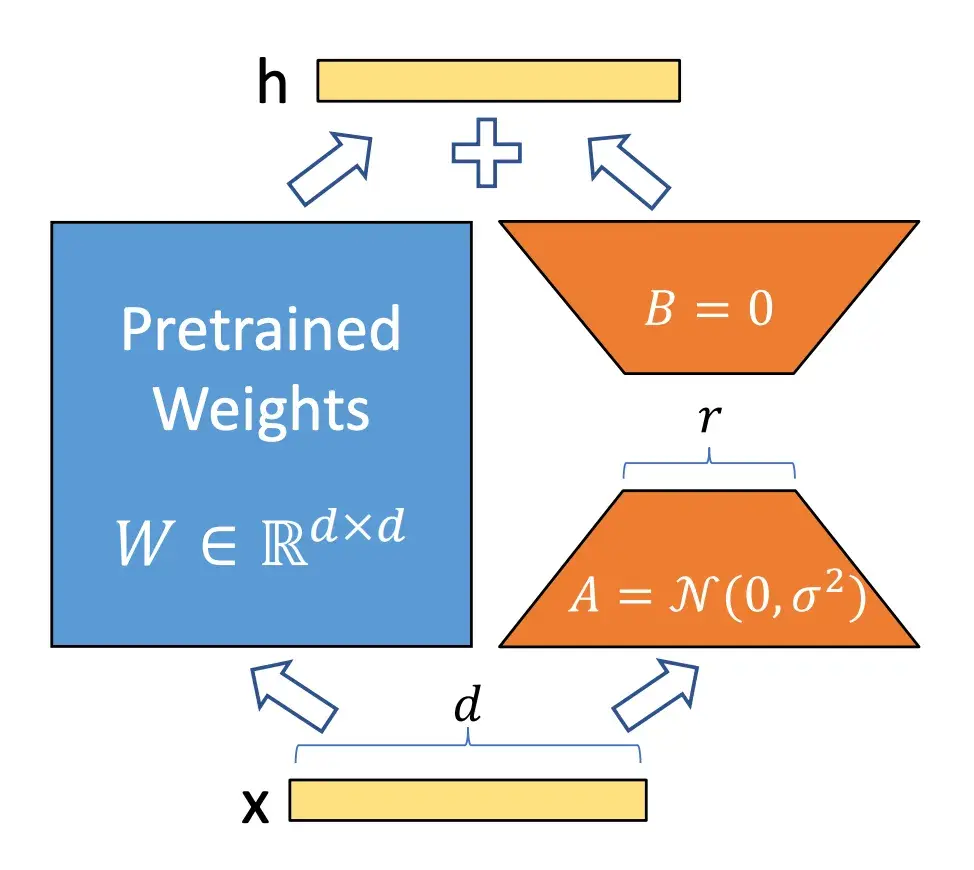
Codex:会写代码的 GPT
论文名称:《Evaluating Large Language Models Trained on Code》
发布时间:2021/07/07
发布单位:OpenAI
阅读重点:HumanEval、unbiased estimator、code fine-tuning
小学生摘要:想象一下,你有一个超级聪明的朋友,他读了很多很多的编程书籍和代码。这个朋友不仅记住了所有内容,还能理解它们,甚至可以自己写出新的代码来解决问题。这就是 Codex,一个由科学家们创造的"超级编程助手"。
Codex就像是把成千上万的程序员的知识都装在了一个大脑里。它学习了GitHub(一个程序员分享代码的网站)上的海量代码,所以它懂得怎么用Python语言编程。
科学家们为了测试Codex有多厉害,给它出了一些编程题目。结果发现,Codex能解决将近三分之一的问题!这比之前的人工智能模型强多了。
有趣的是,如果让Codex多试几次,它解决问题的能力会大大提升。就像你做数学题时,有时候第一次没想出来,多思考几遍就能找到答案一样。
虽然Codex非常厉害,但它也有不足之处。比如,当指令太复杂或者需要灵活运用变量时,它可能会感到困惑。这告诉我们,即使是最先进的人工智能,也还在不断学习和进步中。
科学家们认为,像Codex这样的"超级编程助手"可能会对我们的世界产生重大影响。它可能会改变程序员的工作方式,帮助更多人学习编程,甚至影响到经济和安全等方面。
论文链接:https://arxiv.org/pdf/2107.03374.pdf
核心技术:在 GitHub 上公开可用的代码进行微调的 GPT 语言模型
FLAN:instruction-tuning(指令微调)让模型更了解你想干嘛
论文名称:Finetuned Language Models Are Zero-Shot Learners
发布时间:2021/09/03
发布单位:Google
阅读重点:instruction-tuning、task clusters、instruction templates
小学生摘要:想象你有一个智能助手机器人。这个机器人很聪明,知道很多东西,但是有时候不太明白你具体想让它做什么。
科学家们发现了一个新方法来训练这个机器人,让它变得更聪明、更懂你的意思。这个方法叫做"指令微调"。
这个方法是这样的:
- 科学家们给机器人看了很多不同类型的任务。
- 对每个任务,他们用简单的话告诉机器人该怎么做。
- 他们让机器人练习这些任务很多次。
经过这样的训练后,机器人学会了理解人类的指令。现在,即使你给它一个全新的任务,只要你用简单的话解释清楚,它也能试着去完成。
比如:
- 如果你说"帮我总结一下这篇文章",它就知道要做什么了。
- 如果你说"把这句话翻译成法语",它也能明白你的意思。
更厉害的是,这个新训练出来的机器人(科学家叫它FLAN)在很多任务上,表现得比一些原本更高级的机器人还要好!
科学家们还发现,要把机器人训练得更聪明,有几个重要的点:
- 让机器人学习更多种类的任务
- 用更厉害的机器人来训练
- 用简单、自然的语言来解释任务
论文链接:https://arxiv.org/pdf/2109.01652.pdf

GLaM:用 MoE 架构通过专家混合模型高效扩展语言模型,设计 LLM 准确率更高、训练速度更快
论文名称:《GLaM:Efficient Scaling of Language Models with Mixture-of-Experts》
发布时间:2021/12/13
发布单位:Google
阅读重点:gating module、MoE和dense models比较、数据质量影响、scaling studies
小学生摘要:想象一下,你正在学习一门新的语言。通常情况下,你可能会找一本很厚的教科书,里面包含了所有你需要学习的内容。这本书就像传统的大型语言模型(比如 GPT-3),它包含了大量信息,但你每次学习都需要翻阅整本书,这样既耗时又费力。
现在,Google的研究人员想出了一个更聪明的方法。他们创造了GLaM,这就像是把那本大书分成了许多小册子,每个小册子都由一位"专家"负责。当你需要学习某个特定的内容时,你不需要翻阅整本大书,而是可以直接找到相关领域的"专家"小册子。
这种方法有几个好处:
- 更高效:你不需要每次都看完整本书,只需要查阅需要的部分,这样学习起来更快。
- 节省资源:就像你不需要随身携带整本大书一样,GLaM在工作时不需要使用所有的信息,这样可以节省电脑的能源和计算能力。
- 更聪明:因为每个"专家"小册子都专注于特定的内容,所以它们在各自的领域里可能比一本大而全的书更懂行。这使得GLaM在处理各种语言任务时,表现得比之前的模型更好。
- 可以装下更多知识:用这种方法,研究人员可以创造出比以前大得多的模型,而不会占用太多计算资源。GLaM比GPT-3大约大7倍,但实际使用时却更省资源。
总的来说,GLaM就像是一个超级智能的图书馆,里面有许多专家。当你问它问题时,它会迅速找到最合适的专家来回答,这样既快速又准确,还能节省资源。
论文链接:https://arxiv.org/pdf/2112.06905.pdf
核心技术:GLaM 模型架构
WebGPT:可以上网查资料的 GPT-3 变得更强大
论文名称:《WebGPT:Browser-assisted question-answering with human feedback》
发布时间:2021/12/17
发布单位:OpenAI
阅读重点:environment design、资料demonstrations和comparisons、强化学习和reward modeling
小学生摘要:WebGPT 是一个很厉害的 AI 助手,它可以像人类一样上网查资料来回答问题。想象一下,它就像是一个非常聪明的学生,不仅记住了很多知识,还学会了如何使用搜索引擎来找到更多信息。
这个AI助手是这样被训练出来的:
首先,研究人员让它观察人类是如何使用浏览器搜索信息的,然后模仿这种行为。这就像是你看着老师示范如何查资料,然后自己尝试去做一样。
接着,研究人员会给 AI 的回答打分。如果回答得好,就给它鼓励;如果回答得不够好,就告诉它哪里需要改进。这和老师批改你的作业很像,目的是帮助你做得更好。
AI 在回答问题时,还学会了要说明它是从哪里找到这些信息的。这就像是你写报告时要列出参考资料一样,让别人知道你的信息来源是可靠的。
研究人员还用了一个叫 ELI5的数据集来测试 AI。ELI5的意思是"像我5岁一样解释",里面有很多人们在 Reddit(一个国外的论坛)上问的各种问题。
最后,研究人员发现,在很多情况下,人们更喜欢这个AI给出的回答,甚至比Reddit上最受欢迎的回答还要好。这说明这个AI已经学会了如何给出清晰、有用的解释,就像一个优秀的老师或者学长学姐那样。
论文链接:https://arxiv.org/pdf/2112.09332.pdf
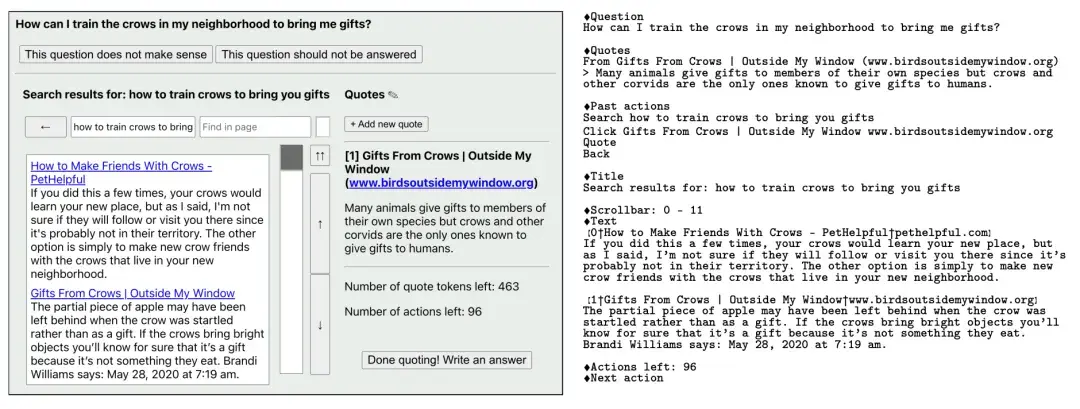
Chain-of-Thought(CoT):给答案要给详解,让 LLM 回答变得更有逻辑、更正确
论文名称:《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》
发布时间:2022/01/28
发布单位:Google
阅读重点:chain-of-Thought Prompting、讨论CoT有效原因
小学生摘要:想象一下,你正在学习解决数学应用题。通常情况下,你可能会直接写出最终答案。但是,如果有人教你先把解题步骤写下来,一步一步地思考,你可能会发现问题变得更容易解决,而且答案也更准确。
科学家们发现,人工智能(AI)也是如此。他们创造了一种叫做"思维链提示"的方法。这个方法就像是在告诉AI:"在给出最终答案之前,先把你的思考过程说出来。"
具体来说,科学家们先给AI看了一些例子,展示如何一步步思考来解决问题。然后,当AI遇到新问题时,它就会模仿这种方式,先列出思考步骤,再得出结论。
结果令人惊讶!经过这样的"训练",AI不仅能更好地解决数学问题,还能更好地理解常识,甚至能进行更复杂的推理。就像你在做数学题时列出步骤可以帮助你更好地解题一样,这种方法也帮助AI变得更聪明了。
这项研究告诉我们,清晰地表达思维过程不仅对人类学习很重要,对人工智能的发展也同样重要。它让我们离创造出真正能够"思考"的AI又近了一步。
论文链接:https://arxiv.org/pdf/2201.11903.pdf
核心技术: 思维链
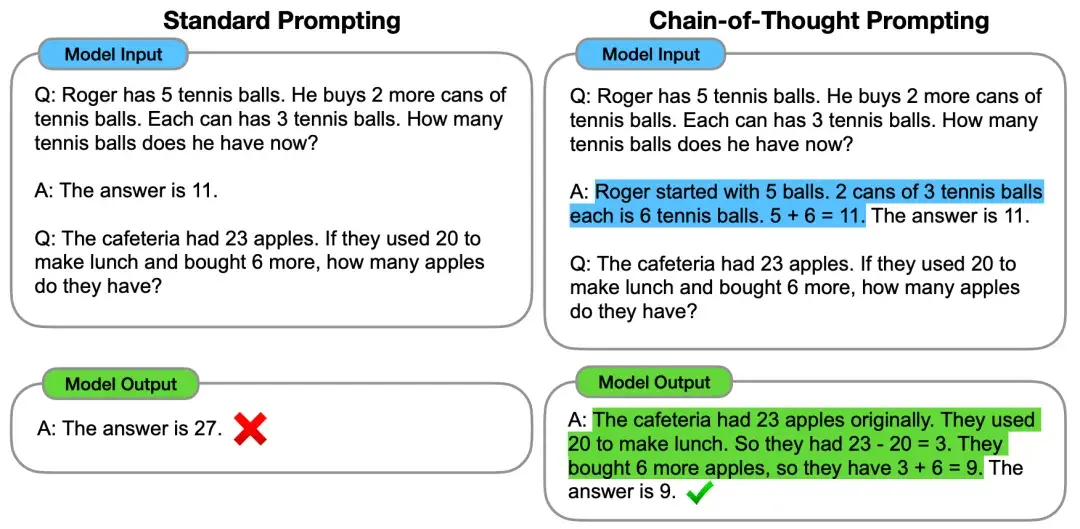
PaLM:训练 LLM 的大型系统
论文名称:《PaLM: Scaling Language Modeling with Pathways》
发布时间:2022/04/05
发布单位:Google
阅读重点:pathways system、discontinuous improvements
小学生摘要:大型语言模型已被证明能够在各种自然语言任务上取得卓越表现,使用了少样本学习(few-shot learning),显著减少了适应特定应用所需的特定训练样本数量。
为了进一步了解规模对少样本学习的影响,我们训练了一个名为 Pathways Language Model(PaLM)的 5400 亿参数的密集激励 Transformer 语言模型。
我们使用 Pathways 这个新的 ML 系统在6144个 TPU v4芯片上进行了 PaLM 的训练,该系统能够实现跨多个 TPU Pod 的高效训练。
我们也展示了通过规模扩展所带来的持续效益,PaLM 540B 在数百个语言理解和生成测试中实现了最新的少样本学习结果。
在其中一些任务中,PaLM 540B 实现了突破性的性能,优于一系列多步推理任务的微调最新技术,并在最近发布的 BIG-bench 测试中超越了人类的平均表现。大量的 BIG-bench 任务显示模型规模的增大带来了不连续的改进,这意味着随着我们扩展到最大的模型,性能会急剧提高。
我们也在各种测试中进行了展示,PaLM 在多语言任务和代码生成方面也具有强大的能力。
此外我们还对偏见和恶意讯息进行了全面分析,并研究了模型规模对训练数据记忆的程度。最后我们讨论了与大型语言模型相关的道德考量,并探讨了潜在的缓解策略。
论文链接: https://arxiv.org/pdf/2204.02311.pdf
InstructGPT:ChatGPT 的前身,让人类来教 GPT-3
论文名称:《Training language models to follow instructions with human feedback》
发布时间:2022/05/04
发布单位:OpenAI
阅读重点:supervised policy、reward model训练、用PPO优化针对reward model的policy
小学生摘要:扩大语言模型的规模并不一定会使其更能理解用户的意图。
举例来说,大型语言模型可能产生不真实、恶意,或者对用户没有帮助的输出。换句话说,这些模型与其用户并不完全一致。
所以在这篇论文中,我们展示了一种通过人类反馈来对语言模型进行微调,从而使其在各种任务中与用户意图保持一致的方法。我们首先从一组由标注者编写的提示和通过OpenAI API提交的提示开始,收集了一组标注者展示所需模型行为的数据集,然后使用监督学习对GPT-3进行微调。接着我们收集了模型输出的排名数据集,进一步使用来自人类反馈的强化学习对这个监督模型进行微调。我们称最终生成的模型为 InstructGPT。
在我们的提示分发的人工评估中,尽管其参数数量少了100倍,拥有13亿参数的InstructGPT模型的输出优于175亿参数的GPT-3的输出。此外InstructGPT模型在真实性上有所提高,在减少恶意输出产生的同时,在公开NLP数据集上几乎没有性能退步。尽管InstructGPT仍然会犯一些简单的错误,但我们的结果显示,通过人类反馈进行微调是使语言模型与人类意图保持一致的一个有前景的方向。
论文链接: https://arxiv.org/pdf/2203.02155.pdf
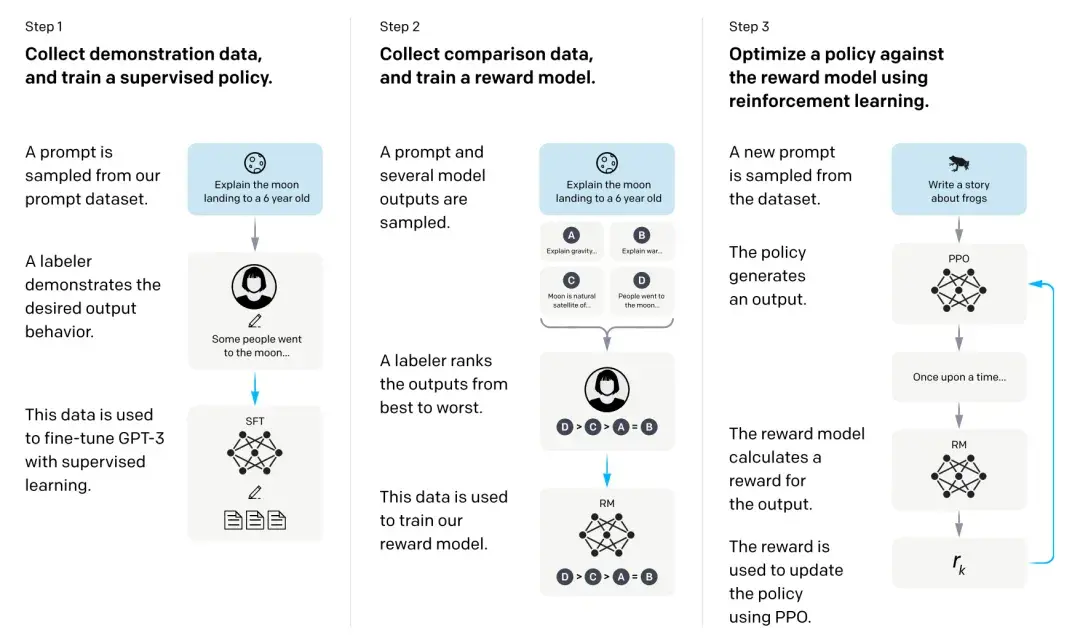
Verify Step by Step:通过监督 LLM 的每一步,让 LLM 数学推理逻辑更强
论文名称:《Let's Verify Step by Step》
发布时间:2022/05/31
发布单位:OpenAI
简单摘要:
阅读重点:outcome-supervised reward models、process-supervised reward models、active learning用在PRM
小学生摘要:想象你正在学习解决复杂的数学题。有两种方法可以帮助你提高:
- 只看最后的答案是对是错 这就像老师只告诉你"答案对了"或"答案错了",但不告诉你哪里做得好,哪里需要改进。
- 检查你解题的每一步 这就像老师仔细查看你的整个解题过程,在每一步都给你建议和指导。
研究人员发现,第二种方法(检查每一步)比第一种方法(只看最后答案)更有效。使用第二种方法,电脑程序能够正确解决78%的难题!
更有趣的是,研究人员还发现了一个提高学习效率的小技巧:让电脑自己选择它最不确定的问题来学习。这就像你在做习题时,主动选择自己觉得最难的题目来练习,这样可以学得更快、更好。
总的来说,这项研究告诉我们,学习复杂知识时,得到每一步的指导和反馈,比只知道最后结果对错要好得多。而且,主动选择具有挑战性的问题来学习,可以帮助我们进步更快。
论文链接: https://arxiv.org/pdf/2305.20050.pdf
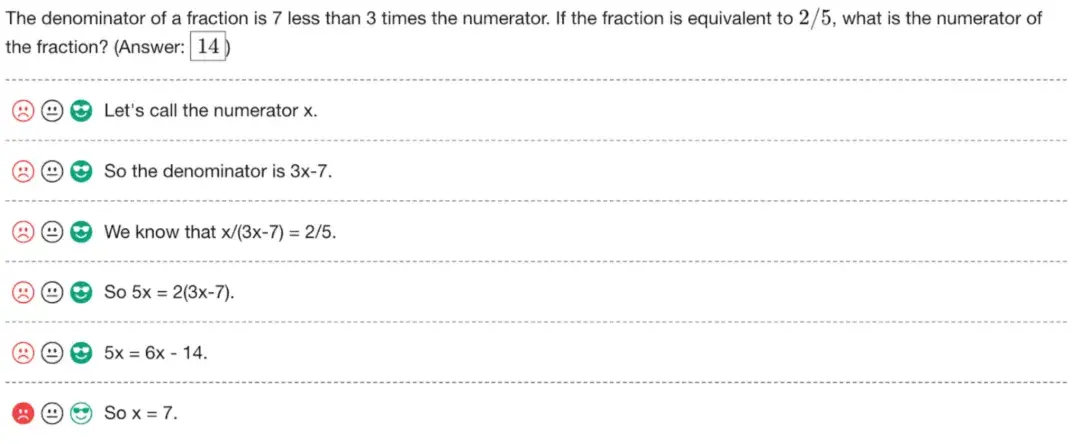
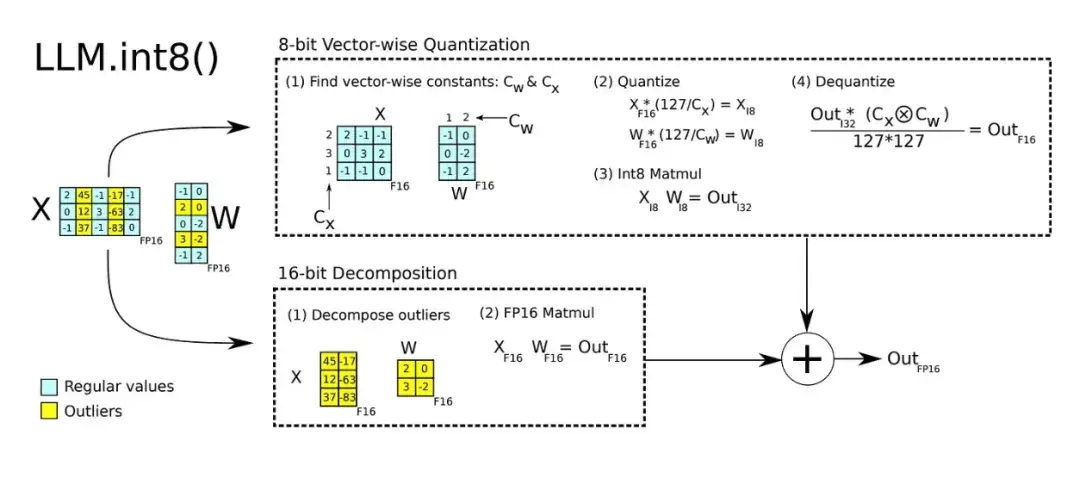
LLM.int8():把 float 16/32 精度的 LLM 转成 int 8,GPU 就跑得动了
论文名称:《LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale》
发布时间:2022/08/15
发布单位:Facebook(Meta)、华盛顿大学、Hugging Face
阅读重点:8-bit quantization、matrix nultiplication、vector-wise quantization、mixed-precision decomposition
小学生摘要:大型语言模型被广泛采用,但推断过程需要大量 GPU 内存。
所以我们开发了一种Int8矩阵乘法程序,适用于transformer中的前馈和注意力投影层,将推断所需的内存减少了一半,同时保持完整的精确度表现。
透过我们的方法,可以加载175B参数的16/32位检查点,转换为Int8,并立即使用,而不会有性能下降。这是因为我们理解和处理了transformer语言模型中高度系统化的新特征,这些特征主导了注意力和预测性能。
为应对这些特征,我们开发了LLM.int8()的两部分量化程序。首先我们使用矢量量化,为矩阵乘法中的每个内积使用单独的归一化常数,对大多数特征进行量化。然而对于新出现的极端值,我们还包括一种新的混合精度分解方案,将这些特异特征维度分离出一个16位矩阵乘法,而仍然有超过99.9%的值在8位中进行乘法。透过LLM.int8(),我们实证表明可以在具有175B参数的LLMs中进行推断,而不会有任何性能下降。这一结果使得这样的模型更加易于使用,例如在单个使用消费级GPU的服务器上使用OPT-175B/BLOOM。
论文链接: https://arxiv.org/pdf/2208.07339.pdf
ReAct:结合思维链提示和行动计划生成,防止 LLM 胡言乱语
论文名称:《ReAct: Synergizing Reasoning and Acting in Language Models》
发布时间:2022/10/06
发布单位:Google、普林斯顿大学
阅读重点:Synergizing Reasoning、Acting、knowledge-intensive reasoning tasks
小学生摘要:大型语言模型(LLMs)在语言理解和互动决策方面展现了令人印象深刻的能力,但它们的推理能力(例如思维链提示)和行动能力(例如行动计划生成)主要是作为独立的主题来研究的。
所以本文探讨了LLMs以交叉方式生成推理跟踪和特定任务的行动,让两者之间更协同:推理跟踪帮助模型诱导、追踪、更新行动计划并处理异常情况,而行动则允许它与知识库或环境等外部来源互动,收集额外讯息。
我们的方法名为ReAct,在多种语言和决策任务上展示了比最先进基准更有效的效果,同时相较于没有推理或移动元件的方法,具有更好的人类可解释性和可信度。
具体来说在问答(HotpotQA)和事实验证(Fever)方面,ReAct通过与简单的维基百科API互动,克服了思维链推理中出现的幻觉和错误传播问题,生成了更具可解释性的人类化任务解决轨迹,优于没有推理跟踪的基准。在两个交互式决策基准(ALFWorld和WebShop)上,即使只提示了一两个上下文示例,ReAct的成功率分别比模仿学习和强化学习方法提高了34%和10%。
论文链接: https://arxiv.org/pdf/2210.03629.pdf

Toolformer:会使用外部工具的 LLM
论文名称:《Toolformer: Language Models Can Teach Themselves to Use Tools》
发布时间:2023/02/09
发布单位:Facebook(Meta)、庞培法布拉大学
阅读重点:sampling API calls、executing API calls、filtering API calls、annotation with self-supervised learning
小学生摘要:这份研究探讨语言模型(LMs)在解决新任务时展现出的惊人能力,仅需少量范例或文本指令即可,并尤其在大规模下表现卓越。
然而相反地,它们在基本功能上表现出困难,例如算术或事实查询,这些功能在更简单、更小型的模型中表现出色。
所以在这篇论文中,我们展示了语言模型可以通过简单的API,自我学习使用外部工具,实现两者之间的最佳结合。
我们引入了Toolformer,这是一个训练过的模型,能够决定调用哪些API、何时调用它们、传递什么参数,以及如何最佳地将结果整合到未来的标记预测中。这是通过自我监督的方式完成的,每个API仅需少量范例即可。我们包含了一系列工具,包括计算机、问答系统、两种不同的搜索引擎、翻译系统和日历。Toolformer在各种下游任务中取得了显著提升的零样本性能,通常与更大的模型竞争力相当,同时也不损害其核心语言模型能力。
论文链接: https://arxiv.org/pdf/2302.04761.pdf

LLaMA:最有名的开源 LLM 第一代
论文名称:《LLaMA: Open and Efficient Foundation Language Models》
发布时间:2023/02/27
发布单位:Facebook(Meta)
阅读重点:pre-training data、architecture、efficient implementation
小学生摘要:我们推出了 LLaMA,这是一系列参数从7B 到65B 的基础语言模型。
我们使用公开可用的数据集训练这些模型,并展示了可以在仅使用公开数据集的情况下训练出最先进的模型,无需使用专有或无法取得的数据集。
特别是LLaMA-13B在大多数基准测试中优于GPT-3(175B),而LLaMA-65B与最佳模型Chinchilla-70B和PaLM-540B竞争力相当。我们将所有模型释出给研究社区使用。
论文链接: https://arxiv.org/pdf/2302.13971.pdf

GPT-4:目前世界上最强的 LLM(我觉得是sonnet)
论文名称:《GPT-4 Technical Report》
发布时间:2023/05/15
发布单位:OpenAI
简单摘要:目前世界上最强的LLM
小学生摘要:我们开发了 GPT-4,这是一个大规模、多模态模型,能够接受图像和文字输入并生成文字输出。
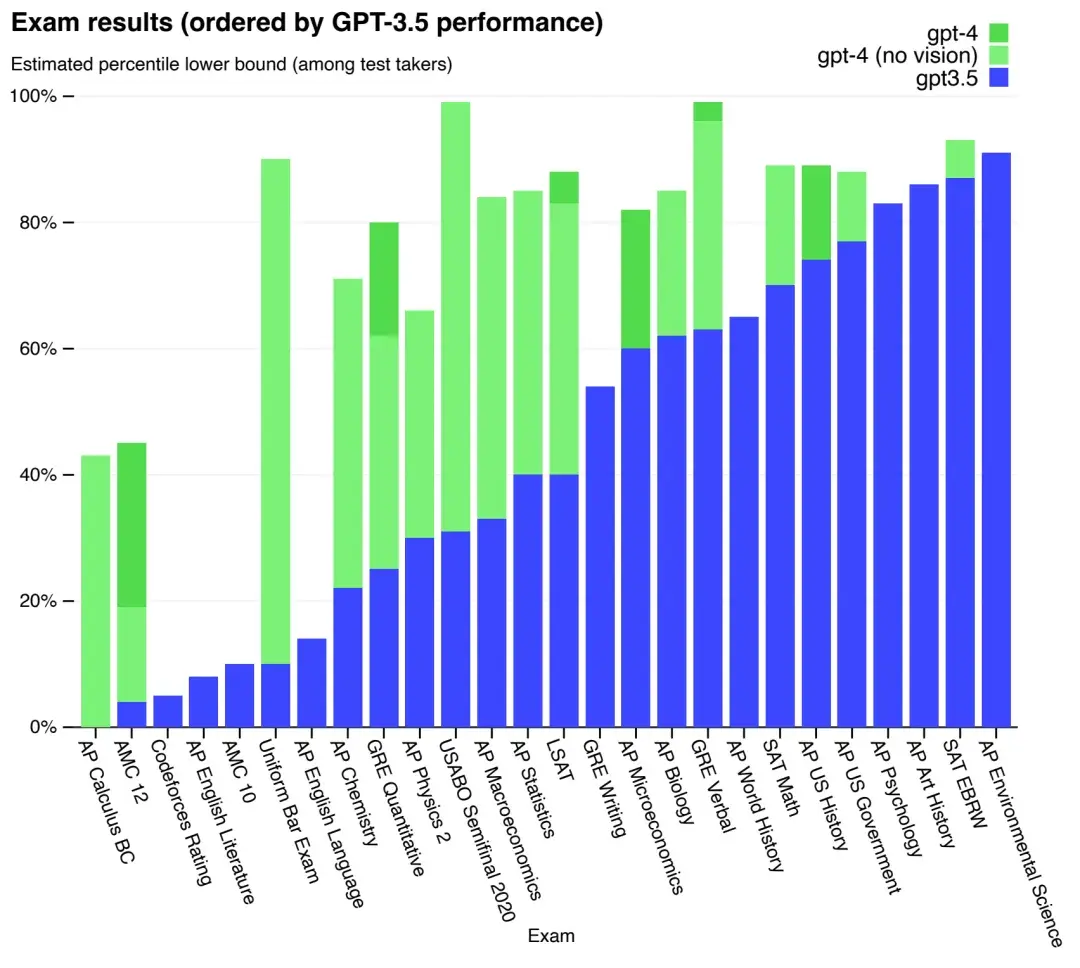
虽然在许多现实情境中比不上人类的能力,但在各种专业和学术基准测试中,GPT-4表现出与人类相当的水平,包括在模拟的律师考试中取得了排名前10%左右的成绩。
GPT-4是一个基于 Transformer 的模型,预先训练来预测文件中的下一个标记。后训练对齐流程改进了模型的事实性和符合期望行为的表现。这个项目的核心部分是开发了在各种规模下都表现稳定的基础设施和优化方法。这使我们能够根据使用不到 GPT-4 1/1,000的计算资源所训练的模型,准确预测 GPT-4的某些性能方面。
论文链接: https://arxiv.org/pdf/2303.08774.pdf
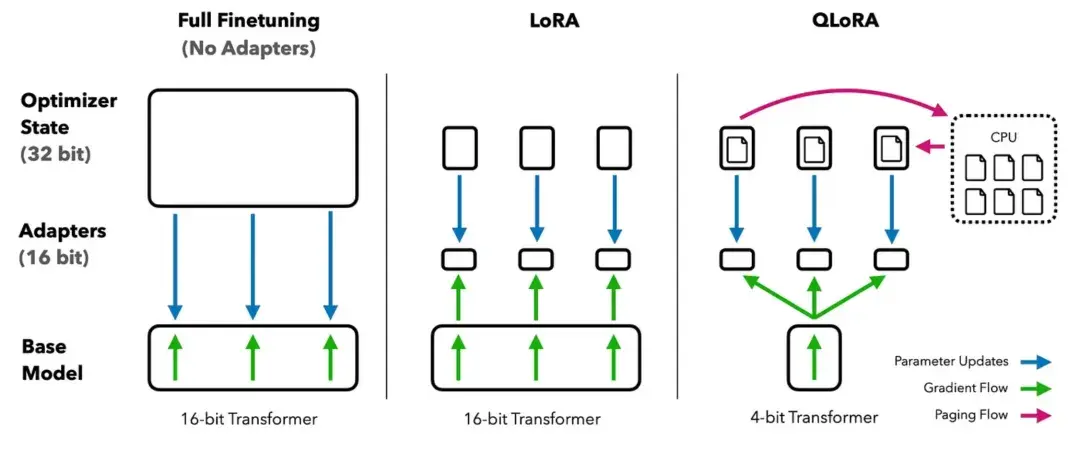
QLoRA:quantization+Lora 让我一张显卡就可 fine-tune LLM
论文名称:《QLoRA: Efficient Finetuning of Quantized LLMs》
发布时间:2023/05/23
发布单位:华盛顿大学
阅读重点:4-bit NormalFloat、double quantization、paged optimizers
小学生摘要:我们提出了 QLoRA,一种有效的微调方法,可以减少内存使用量,让一个65B 参数的模型在一个48GB 的 GPU 上进行微调,同时保持完整的16位微调任务性能。
QLoRA通过一种称为Low Rank Adapters(LoRA)的方法,将梯度反向传播到冻结的4位量化预训练语言模型。我们最佳的模型家族名为Guanaco,在Vicuna基准测试中表现优于以往所有公开发布的模型,并仅需在单个GPU上进行24小时的微调即可达到ChatGPT 99.3%的性能水平。
QLoRA 引入了几项创新,以节省内存而不影响性能:
- 4位 NormalFloat(NF4),这是一种对于正常分布权重的训息理论最优的新数据类型;
- 双重量化,通过量化量化常数来减少平均内存占用;
- 标签优化器,管理内存峰值。我们使用 QLoRA 对 1000 多个模型进行微调,提供了对 8 个指令数据集、多种模型类型(LLaMA、T 5)以及使用常规微调不可行的模型规模(例如 33 B 和 65 B 参数模型)的指令遵从和聊天机器人性能的详细分析。
我们的结果表明,QLoRA 在一个小而高质量的数据集上进行微调,即使使用的模型比以前的模型更小,可以达到最新技术水平的性能。除此之外我们提供了基于人类和 GPT-4评估的聊天机器人性能的详细分析,并显示 GPT-4评估是一种便宜且合理的替代方法。
此外我们发现当前的聊天机器人基准测试不能准确评估聊天机器人的性能水平。通过某些方面的分析,我们展示了 Guanaco 相对于 ChatGPT 的不足之处。最后我们释出了所有模型和代码,包括4位训练的 CUDA 核心。
论文链接: https://arxiv.org/pdf/2305.14314.pdf
Phi-1:高品质的小数据胜过大数据和大模型
论文名称:《Textbooks Are All You Need》
发布时间:2023/06/20
发布单位:Microsoft
阅读重点:importance of high-quality data、用 transformer 过滤 datasets、synthetic textbook-quality datasets、data pruning
小学生摘要:我们推出了 phi-1,一款针对代码的新型大型语言模型,规模远小于竞争对手的模型:phi-1是一个基于 Transformer 的模型,拥有 13 亿参数,在 8 个 A100 GPU 上训练了 4 天,使用了来自网络“教科书级别”的数据(60亿标记)和使用 GPT-3.5 合成生成的教科书和练习题(10亿标记)。
尽管规模小,phi-1 在 HumanEval 上达到了 50.6% 的 pass@1 准确率,以及 MBPP 上的 55.5%。与 phi-1-base 相比(我们在编程练习数据集上进行微调之前的模型),phi-1 也展现了令人惊讶的新特性,以及与 phi-1-small(另一个具有 3.5 亿参数的较小模型)相比的性能,后者在 HumanEval 上仍然达到了 45%。
论文链接:https://arxiv.org/pdf/2306.11644.pdf
RLAIF:让社会化的 LLM 来社会化 LLM
论文名称:《RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback》
发布时间:2023/08/24
发布单位:Google
阅读重点:reference labeling with LLMs、addressing position bias、distilled RLAIF、direct RLAIF、evaluation
小学生摘要:强化学习从人类反馈中学习(RLHF)已被证明能有效让大型语言模型(LLMs)与人类偏好保持一致。
然而收集高质量的人类偏好标签可能耗时且昂贵。前人所提出的AI反馈强化学习(RLAIF)提供了一种有希望的替代方案,它利用强大的现成LLM来生成偏好,取代了人类标注者。
在摘要、有帮助的对话生成和无害对话生成等任务中,RLAIF获得了与RLHF相当或更优的表现。此外在另一个实验中,直接向LLM提供奖励分数的提示方法,即使LLM偏好标注生成器与策略大小相同,也能比典型的RLAIF设置获得更好的表现。最后我们对生成符合AI偏好的技术进行了广泛研究。我们的结果表明,RLAIF能达到人类水平的性能,为克服RLHF的扩展性限制提供了潜在解决方案。
论文链接: https://arxiv.org/pdf/2309.00267.pdf
Superalignment:要人类能监督超级 AI,先从小 LLM 监督大 LLM 开始
论文名称:《Weak-to-Strong Generalization: Eliciting Strong Capabilities with Weak Supervision》
发布时间:2023/12/14
发布单位:OpenAI
小学生摘要:广泛使用的对齐技术,比如从人类反馈中进行强化学习(RLHF),依赖于人类监督模型行为的能力,例如评估模型是否忠实地遵从指令或生成安全的输出。
但是未来的超级人工智能模型将表现出复杂的行为,对人类来说难以可靠地评估,对于人类对超级人工智能模型进行弱监督,我们研究了这个问题的类比:弱模型监督是否能唤起更强大模型的全部能力?
我们在自然语言处理、西洋棋和奖励建模任务上使用了一系列GPT-4系列的预训练语言模型进行测试。
我们发现,当我们用弱模型生成的标注来简单微调强大的预训练模型时,它们的表现一直优于弱监督模型,我们称之为弱到强泛化现象。然而仅仅通过简单微调,我们仍然离完全发挥强大模型的能力很远,这表明像RLHF这样的技术在不进一步研究的情况下可能无法应对超级人工智能模型的挑战。我们发现简单的方法通常能显著提高弱到强泛化能力:例如当用GPT-2级别的监督模型和辅助的置信损失来微调GPT-4时,我们在NLP任务上可以接近GPT-3.5的性能水平。我们的结果表明,当前在解决对齐超级人工智能模型方面是有可能取得实际进展的。
论文链接:https://cdn.openai.com/papers/weak-to-strong-generalization.pdf
GraphRAG:知识图谱检索增强
论文名称:《From Local to Global: A Graph RAG Approach to Query-Focused Summarization》
发布时间:2024/04
发布单位:Microsoft
中文摘要:使用检索增强生成(RAG)从外部知识源检索相关信息,使大型语言模型(LLM)能够回答关于私人和/或以前看不到的文档集合的问题。
然而,RAG在针对整个文本语料库的全局问题上失败了,例如“数据集中的主要主题是什么?”,因为这本质上是一个以查询为重点的总结(QFS)任务,而不是一个明确的检索任务。与此同时,以前的QFS方法未能扩展到典型的RAG系统索引的文本数量。
为了结合这些对比方法的优势,我们提出了一种图形RAG方法,在私人文本语料库上回答问题,该方法可根据用户问题的一般性和要索引的源文本的数量进行缩放。
我们的方法使用LLM分两个阶段构建基于图形的文本索引:首先从源文档中导出实体知识图形,然后为所有密切相关的实体组预先生成社区摘要。给定一个问题,每个社区摘要都用于生成部分响应,然后将所有部分响应再次汇总到对用户的最终响应中。对于一类关于100万令牌范围内数据集的全球意义问题,我们表明,Graph RAG在生成答案的全面性和多样性方面比天真的RAG基线有了实质性改进。
论文链接:https://arxiv.org/pdf/2404.16130

PS:以下为有关论文的 github 合集 https://github.com/dair-ai/ML-Papers-Explained