
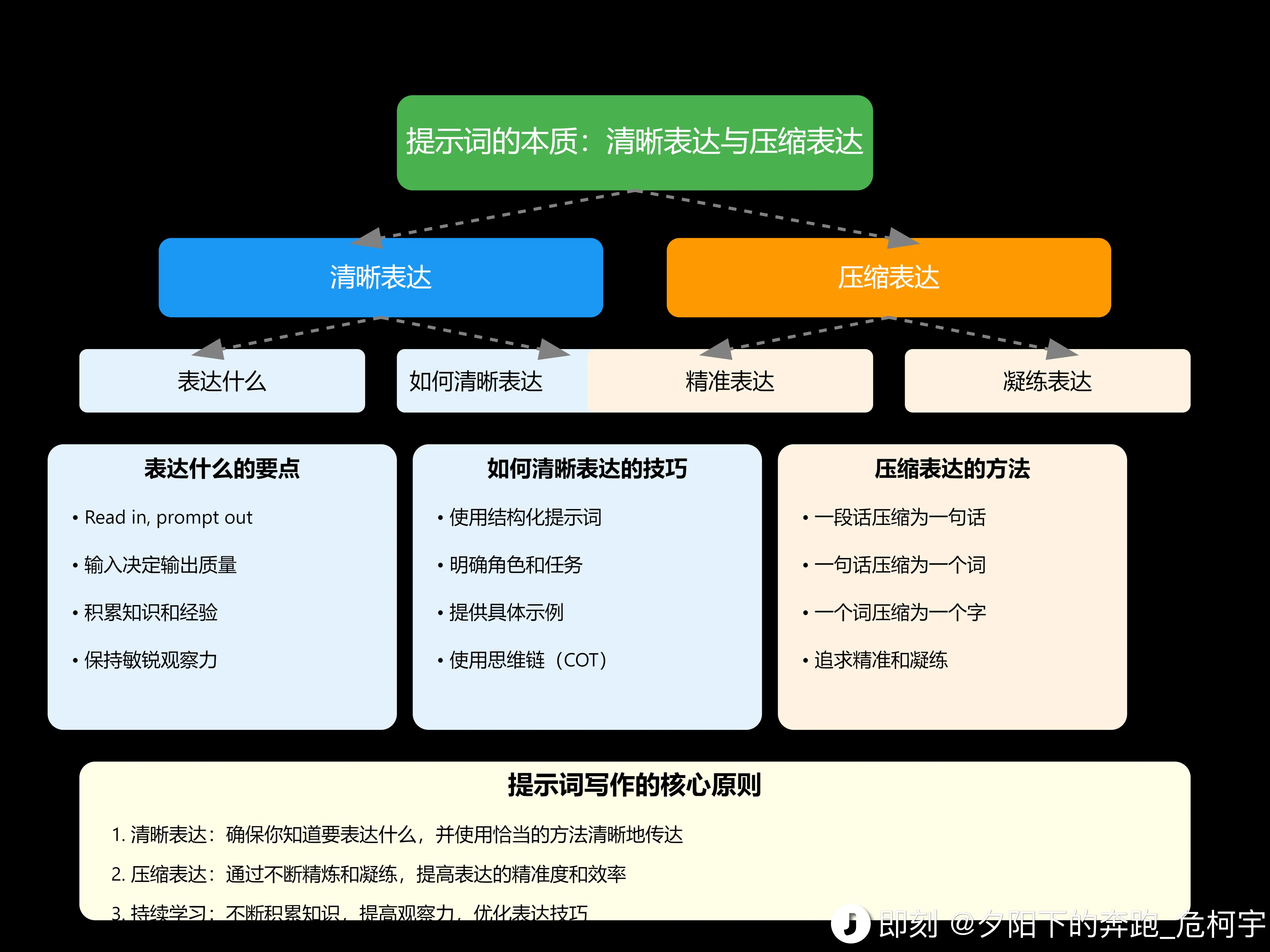
看过一些 o1 的文章介绍之后的感想&总结:
一、预训练 Scaling Law 正式翻篇,推理 Scaling Law (Self-play RL)正式开始,所以推理时间久,而且刚开始就具备博士级别的能力
二、Prompt 编写范式变化:简单、层次清晰,但能力更强。这点结合群友刚哥的 Claude 提示词卡片就可以看出,将是未来提示词最大的发展趋势了。
- Prompt 编写范式变化 1. 新的 O1 内置 Agent 和 CoT,可以判断思考结果是正确还是错误,所以无需人工添加 CoT
- O1 擅长提供清晰的指令,更少的 Prompt 和 RAG 上下文解决问题,可以使用 xml、lisp 等语言分隔让层次更清晰
- 很多需要分解为多步 Agentic Workflow 的,目前可能一个 API 搞定
三、推理(数学+编程)革命性突破,文字创作可能更差
- 推理能力提升带来的范式变化
- 可解决复杂的数学问题或者多步依赖条件问题,因为能判断结果正误,比如微信数字生命卡兹克给出的例子「调休例子」、「奥数题」 https://mp.weixin.qq.com/s/edpeHU_q6I4BPmHE2-daIQ…
- 逻辑创作能力:比如海龟汤问题,需要逻辑判断来撰写故事,这类问题能很好的解决,悬疑故事新解?!🤔
- 推理时间带来产品设计的思考
- 目前 O 1 Preview 回答一个问题大概需要思考 15~2 分钟,意味着场景从实时 Copilot/Chatbot 场景抽离出来,可能迈向更多异步、或者本身就是很难的多步复杂任务处理(用户愿意付更多钱)
四、OpenAI 公布的研究很少,但是社区已经有一些有意思的工作与论文
- 研究推理阶段的 Scaling Law https://arxiv.org/abs/2407.21787v1…
- Q* 灵感:https://arxiv.org/abs/2403.09629
- LLM 推理:https://arxiv.org/html/2403.04121v1…
- 更多的推理计算 https://arxiv.org/abs/2408.00724 \
- Alpha 蒙特卡洛搜索 https://arxiv.org/pdf/2309.17179
- OpenAI O 1 的进步本质上是将 AlphaGo 的成功复制到 LLM 的胜利,即 RL-based 蒙特卡洛搜索等技术参考:https://mp.weixin.qq.com/s/pNY3jc3hj5aBp8lESJxlhA
- OpenAI 发布 O 1 时,录制了很多宣传短篇,特工宇宙的小伙伴连夜赶工出了中文翻译版本,非常赞👍 https://agentuniverse.feishu.cn/wiki/E7IIwVABoiKS7LkExDfc8tGInqh…
OpenAI o1 是大模型的巨大进步
我觉得 OpenAI o1是自 GPT 4发布以来,基座大模型最大的进展,逻辑推理能力提升的效果和方法比我想的要好,GPT 4o 和 o1是发展大模型不同的方向,但是 o1这个方向更根本,重要性也比 GPT 4o 这种方向要重要得多,原因下面会分析。
为什么说 o1比4o 方向重要?这是两种不同的大模型发展思路,说实话在看到 GPT 4o 发布的时候我是有些失望的,我当时以为 OpenAI 会优先做 o1这种方向,但是没想到先出了 GPT 4o。GPT 4o 本质上是要探索不同模态相互融合的大一统模型应该怎么做的问题,对于提升大模型的智力水平估计帮助不大;而 o1本质上是在探索大模型在 AGI 路上能走多远、天花板在哪里的问题,很明显第二个问题更重要。
GPT 4o 的问题在于本身大模型的智力水平还不够高,所以做不了复杂任务,导致很多应用场景无法实用化,而指望靠图片、视频这类新模态数据大幅提升大模型智力水平是不太可能的,尽管确实能拓展更丰富的多模态应用场景,但这类数据弥补的更多是大模型对外在多模态世界的感知能力,而不是认知能力。提升大模型认知能力主要还要靠 LLM 文本模型,而提升 LLM 模型认知能力的核心又在复杂逻辑推理能力。LLM 的逻辑推理能力越强,则能解锁更多复杂应用,大模型应用的天花板就越高,所以不遗余力地提升大模型尤其是文本模型的逻辑能力应该是最重要的事情,没有之一。
如果 o1模型能力越做越强,则可以反哺 GPT 4o 这种多模态大一统模型,可以通过直接用 o1基座模型替换 GPT 4o 的基座、或者利用 o1模型生成逻辑推理方面的合成数据增强 GPT 4o、再或者用 o1蒸馏 GPT 4o 模型….. 等等,能玩的花样应该有很多,都可以直接提升 GPT 4o 的复杂任务解决能力,从而解锁更复杂的多模态应用场景。OpenAI 未来计划两条线,一条是 o1,一条是 GPT 4o,它的内在逻辑大概应该是这样的,就是说通过 o1增强最重要的基座模型逻辑推理能力,而再把这种能力迁移到 GPT 4o 这种多模态通用模型上。
OpenAI o1的做法本质上是 COT 的自动化。我们知道,通过 COT 把一个复杂问题拆解成若干简单步骤,这有利于大模型解决复杂逻辑问题,但之前主要靠人工写 COT 来达成。从用户提出的问题形成树的根结点出发,最终走到给出正确答案,可以想像成类似 AlphaGo 下棋,形成了巨大的由 COT 具体步骤构成的树形搜索空间,这里 COT 的具体步骤的组合空间是巨大的,人写的 COT 未必最优。如果我们有大量逻辑数据,是由<问题,明确的正确答案>构成,则通过类似 AlphaGo 的 Monte Carlo Tree Search 搜索+强化学习,确实是可以训练大模型快速找到通向正确答案的 COT 路径的。而问题越复杂,则这个树的搜索空间越大,搜索复杂度越高,找到正确答案涉及到的 COT 步骤越多,则模型生成的 COT 就越复杂,体现在 o1的速度越慢,生成的 COT Token 数越多。很明显,问题越复杂,o1自己生成的隐藏的 COT 越长,大模型推理成本越高,但效果最重要,成本其实不是问题,最近一年大模型推理成本降低速度奇快,这个总有办法快速降下去。
从上面 o1的做法可以知道Prompt 工程会逐渐消亡。之前解决复杂问题,需要人写非常复杂的 Prompt,而 o1本质上是 COT 等复杂 Prompt 的自动化,所以之后是不太需要用户自己构造复杂 Prompt 的。本来让用户写复杂 Prompt 就是不人性化的,所有复杂人工环节的自动化,这肯定是大势所趋。
Agent 属于概念火但无法实用化的方向,主要原因就在于基座模型的复杂推理能力不够强。如果通过基座模型 Plan 把一个复杂任务分解为10个步骤,哪怕单个步骤的正确率高达95%,要想最后把任务做对,10个环节的准确率连乘下来,最终的正确率只有59%,惨不忍睹。那有了 o1是不是这个方向就前途坦荡?也是也不是,o1的 Model Card 专门测试了 Agent 任务,对于简单和中等难度的 Agent 任务有明显提升,但是复杂的、环节多的任务准确率还是不太高。就是说,不是说有了 o1 Agent 就现状光明,但是很明显 o1这种通过 Self Play 增强逻辑推理能力的方向应该还有很大的发展潜力,从这个角度讲说 Agent 未来前途光明问题应该不大。
OpenAI 很多时候起到一个行业指路明灯的作用,往往是第一个证明某个方向是行得通的(比如 ChatGPT、GPT 4、Sora、GPT 4o 包括这次的 o1),然后其他人开始疯狂往这个方向卷,到后来甚至卷的速度太快把 OpenAI 都甩到后面吃尾气。典型例子就是 Sora,如果 OpenAI 不是出于阻击竞争对手秀一下肌肉,大家都没有意识到原来这个方向是可以走这么远的,但当意识到这一点后,只要你专一地卷一个方向,方向明确且资源聚焦,是可能赶超 OpenAI 的,目前国内外各种视频生成模型有些甚至可能已经比 Sora 好了,Sora 至今仍然是期货状态,主要 OpenAI 想做的方向太多,资源分散导致分到具体一个方向的资源不够用,所以越往后发展期货状态的方向越多,也让人觉得尽显疲态。
OpenAI o1等于给大家又指出了一个前景光明的方向,估计后面大家又开始都往这个方向卷。我觉得卷这个方向比去卷 GPT 4o 和视频生成要好,虽然具体怎么做的都不知道,但是大方向清楚且效果基本得到证明,过半年肯定头部几家都能摸清具体技术追上来,希望能再次让 OpenAI 吃尾气。而且这个方向看上去资源耗费应该不会特别大,偏向算法和数据一些,数据量规模估计不会特别巨大,卷起来貌似成本低一些。这是个卷的好方向。
预训练 Scaling Law 为何一定会变缓
粗分的话,大语言模型最基础的能力有三种:语言理解和表达能力、世界知识存储和查询能力以及逻辑推理能力(包括数学、Coding、推理等理科能力,这里 Coding 有一定的特殊性,是语言能力和逻辑掺杂在一起的混合能力,Coding 从语言角度可以看成一种受限的自然语言,但是混杂着复杂的内在逻辑问题。从语言角度看,Coding 貌似是容易解决的,从逻辑角度看又相对难解决。总之,Coding 目前看是除了语言理解外,大模型做得最好的方向)。
语言理解和表达是 LLM 最强的能力,初版 ChatGPT 就可以完全胜任各种纯语言交流的任务,基本达到人类水准,目前即使是小模型,在这方面比大模型能力也不弱;世界知识能力虽说随着模型规模越大效果越好,但幻觉问题目前无法根治,这是制约各种应用的硬伤之一;逻辑推理能力一直都是 LLM 的弱项,也是最难提升的方面,从 GPT 4开始往后,如何有效并大幅提升 LLM 的逻辑推理能力是体现不同大模型差异和优势的最核心问题。所以,大模型最重要的一个是世界知识方面如何有效消除幻觉,一个是如何大幅提升复杂逻辑推理能力。语言能力已不是问题。
从大模型的基础能力,我们再说回已经被谈滥了的大模型 Scaling law。现在普遍认为通过增加数据和模型规模来提升大模型效果的 Scaling law 模式,其增长速度在放缓。其实我们对照下大模型的三个基础能力的能力来源,基本就能看出来这是为啥(以下是我猜的,不保真):
本质上大模型的能力来源都来自训练数据,包含能体现这方面能力的训练数据越多,则这种能力越强。语言能力不用说了,任意一份预训练数据,其中都包含相当比例的语言的词法句法等成分,所以训练数据中体现语言能力的数据是最多的,这也是为何大模型的语言能力最强的原因。
而数据中包含的世界知识含量,基本是和训练数据量成正比的,明显数据量越多,包含的世界知识越多,Scaling law 是数据中包含的世界知识含量关系的一个体现,但是这里有个问题,大模型见过越多数据,则新数据里面包含的新知识比例越小,因为很多知识在之前的数据里都见过了,所以随着数据规模增大,遇到的新知识比例就越低,在世界知识方面就体现出 Scaling law 的减缓现象。
而为啥逻辑推理能力最难提升?因为能体现这方面的自然数据(代码、数学题、物理题、科学论文等)在训练数据中比例太低,自然大模型就学不好,尽管通过不断增加数据,能增加逻辑推理方面数据的绝对数量,但因为占比太少,这方面提升的效果和增加的总体数据规模就不成比例,效果也不会太明显,就体现在逻辑推理能力 Scaling law 看上去的放缓。这是很自然的。这也是为何现在为了提高模型逻辑能力,往往在预训练阶段和 Post-training 阶段,大幅增加逻辑推理数据占比的原因,且是有成效的。
o1的 RL 有 Scaling Law 吗?
所以目前大模型的核心能力提升,聚焦到不断通过合成数据等方式构造更多比例的逻辑推理数据上来。但是大部分逻辑推理数据的形式是<问题,正确答案>,缺了中间的详细推理步骤,而 o1本质上是让大模型学会自动寻找从问题到正确答案的中间步骤,以此来增强复杂问题的解决能力。
OpenAI o1提到了关于 RL 在训练和推理时候的 Scaling law,并指出这与预训练时候的 Scaling law 具有不同特性。很明显,如果 o1走的是 MCTS 路线,那么把 COT 拆分的越细(增加搜索树的深度),或提出更多的可能选择(节点的分支增多,就是说树的宽度越宽),则搜索空间越大,找到好 COT 路径可能性越大,效果越好,而训练和推理的时候需要算力肯定越大。看上去有着效果随着算力增长而增长的态势,也就是所谓的 RL 的 Scaling law。这其实是树搜索本来应有之义,我倒觉得把这个称为 RL 的 Scaling law 有点名不副实。
OpenAI 首席科学家揭示 o1 模型训练核心秘密
在他的演讲中,他提出了类比“教人钓鱼”的方式,强调激励学习的重要性:“授人以鱼,不如授人以渔”,但是更进一步的激励应该是: “让他知道鱼的美味,并让他保持饥饿”,这样他就会主动去学习如何钓鱼。
在这个过程中,他还会学会其他技能,如耐心、阅读天气、了解鱼类等。而其中有些技能是通用的,可以应用到其他任务中。
通过激励来教导比直接教导可能要花费更多时间。对于人类来说确实如此,但对机器来说,可以增加计算量以缩短时间。因为机器可以通过更多的计算资源克服人类时间上的限制,从而在专门领域表现得比专家更好。
这就像在《龙珠》中,有个“精神与时间之屋”,在里面训练一年,外面只过一天,倍率是365。对于机器来说,这个倍数要高得多。因此,它认为通过高效的计算,通才模型在专门领域中也能超越专家。
以下是演讲主要内容总结:
通用智能 vs. 专用智能
Hyung Won Chung 强调了通用智能(General Intelligence)与专用智能(Specialized Intelligence)的区别。专用智能模型是为特定任务设计的,适合处理单一任务,而通用智能模型能够处理广泛的任务,适应各种未知场景。
由于通用智能要求模型具备更强的适应能力,研究者不可能为模型教授每个具体任务。相反,Hyung Won Chung 认为,通过弱激励机制,让模型在大规模数据和计算资源的驱动下自主学习各种技能,才是通往通用智能的可行途径。
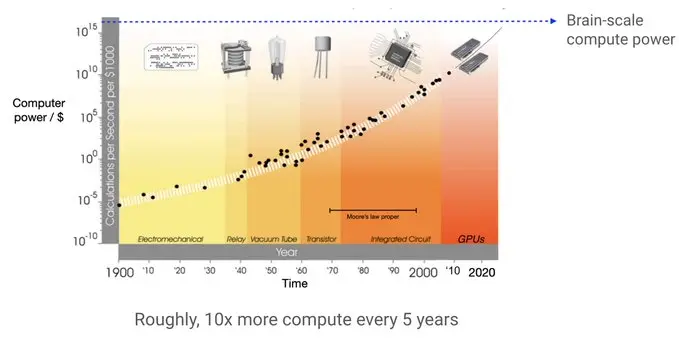
扩展与计算能力的关键作用
Hyung Won Chung 展示了一个重要的数据点:计算能力以指数级增长,成本持续降低。这意味着随着时间的推移,更多的计算资源变得可用,这为 AI 研究提供了巨大的机会。
他指出,AI 研究者的工作是利用这种不断扩大的计算能力,设计可扩展的算法,使模型能够随着计算资源的增加而自动提升性能。与此相对,那些高度结构化的模型虽然在初期可能表现较好,但在规模化时往往会遇到瓶颈。
弱激励学习(Weak Incentive Learning)
目前大规模语言模型,如 GPT-3和 GPT-4,使用的是弱激励学习,例如通过下一个词预测任务来驱动模型的训练。Hyung Won Chung 提出,通过这种任务,模型不仅学会了语言,还掌握了推理、数学和编码等技能,尽管这些技能并没有被直接教授。
他进一步指出,与其直接教给模型某种技能,最好的方法是通过提供弱激励,让模型在面对大量任务时自主发展出解决问题的通用能力。
例如,通过训练模型进行下一个词的预测,模型不但学会了语言结构,还学会了如何在没有明确指令的情况下推理出复杂答案。
涌现能力(Emergent Abilities)
Hyung Won Chung 详细讨论了涌现能力这一现象。随着模型规模的扩大,模型在解决问题时往往会自发地表现出新能力。这些能力并非被人为编码,而是通过模型的自我学习在训练过程中自然涌现出来的。
他用大规模语言模型的例子说明了这一点。在没有直接教授推理或数学的情况下,GPT-4等模型能够表现出复杂的推理能力和数学计算能力。这表明,涌现能力是随着模型规模扩展而自然发生的,尤其是在面对广泛的任务时。
激励结构的设计
Hyung Won Chung 提倡为 AI 模型设计更复杂的激励结构。通过引入更丰富的奖励机制,模型可以学会更高层次的能力。
例如,Hyung Won Chung 提出,为了解决语言模型中的“幻觉问题”(hallucination),可以设计奖励结构,使得模型不仅仅追求回答问题的正确性,还要学会在不确定的情况下说“不知道”。
他指出,通过激励结构,模型可以学会如何判断自己是否知道答案,这种能力对提高模型的可靠性和可信度至关重要。激励结构使模型在大量任务的驱动下学会适应不同的问题情境,并在此过程中发展出更通用的能力。
扩展定义的重新思考
Hyung Won Chung 对“扩展”(Scaling)的定义进行了重新审视。传统意义上的扩展指的是“用更多的机器做相同的事情”,但他认为,这种定义过于狭隘。
他提出了一种更有价值的扩展定义:识别那些限制进一步扩展的假设或结构,并用更具扩展性的方法替代它们。这种扩展不只是增加计算资源,还涉及对模型进行重新设计,使其更好地利用不断增加的计算能力和数据。
持续的“去学习”与适应
随着更强大的模型(如 GPT-4)的推出,AI 领域的基本假设不断变化。Hyung Won Chung 指出,研究者需要具备一种持续“去学习”的能力,以便适应新模型带来的新现实。
他解释说,语言模型的发展使得我们几乎每隔几年就必须抛弃旧的认知,适应新模型带来的新能力。这种去学习的过程对于保持在 AI 领域的领先地位至关重要,因为每次新模型的出现都会改变我们对 AI 的理解和使用方式。
来源参考:Tom Huang、张俊林、Hyung Won Chung