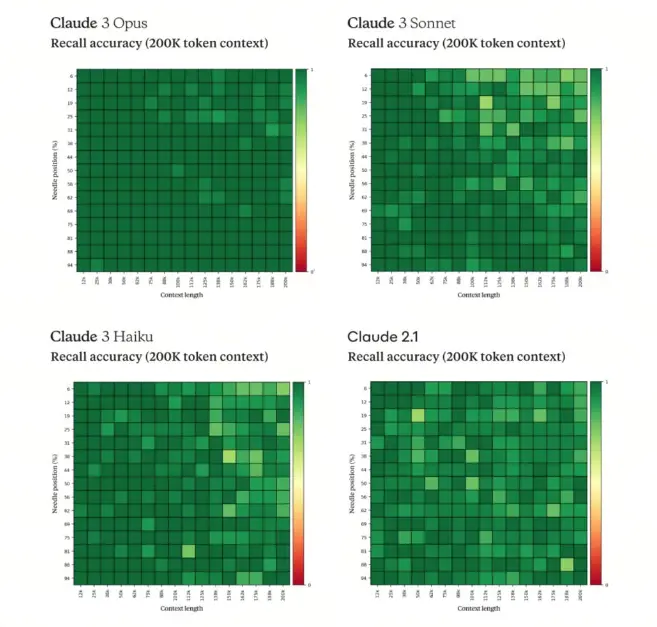
最近发布的 claude 3 支持 200 k 的上下文,简单回顾了一下到 2024 年 3 月 7 号为止超过 100 k 上下文窗口的大模型。
| 模型名 | 最大上下文 | 大海捞针通过率 |
|---|---|---|
| Claude 3 系列 | 100-200 K | >99% |
| Claude 2.1 | 200 K | >50% |
| GPT 4 | 128 K | >95% |
| Yi-34B | 200 K | 无 |
| Baichuan 2 | 200 K | >90% |
| ChatGLM 4 | 192 K | >99% |
| kimi chat | 192 K | >99% |
| XVERSE-Long | 256 K | 无 |
| InternLM | 200 K | 无 |
| Gemini | 100 K | 无 |
长上下文带来的益处
模型性能的提升
- 大型语言模型的上下文窗口扩大到200K tokens,意味着模型可以在单个输入中处理更长的文本。这对于理解长篇文章、书籍、编写更长的内容或进行深入的话题分析具有显著优势。模型能够捕捉到更长文本中的细微联系和结构,从而提高了语言理解和生成的质量。
应用场景的扩展
- 随着上下文窗口的扩大,大型语言模型可以在更多领域中得到应用。例如,在法律和医学领域,专业文档往往篇幅较长,需要模型能够处理大量信息。200K tokens 的上下文窗口能让模型更好地理解和生成这些领域的复杂文档,从而在法律顾问、医疗咨询等高级应用中发挥作用。
计算资源的需求增加
- 扩大上下文窗口意味着在模型训练和推理过程中需要处理更多数据。这将导致计算资源需求显著增加,特别是在内存和处理能力上。为了有效管理这种需求增长,可能需要开发更高效的算法和硬件优化策略。
未来发展方向
- 面对上下文窗口的扩大,未来的研究可能会集中在提高模型效率、开发新的稀疏技术和参数共享策略,以及探索新的模型架构来更好地管理大量信息。此外,如何在保证模型性能的同时减少对计算资源的依赖,也将是未来研究的重要方向。
带来的一些思考
- Rag 最多坚持两年就会被长窗口最终解决掉?
- 长上下文发展会一定会简化 rag
- 比如数据库有 10 T 数据,显式 RAG 做检索抽出 1 k token,相当于一个 10 T 的窗口,其中 10 T-1 k 的 kv 都被 mask 掉,后续文本仅和 1 k token 长度的 kv 算注意力
- Rag 抽出 1 k 数据一定是有损的,简单说就是永远不能确定真正有用的信息是否在这 1 k 里,所以 long context 至少在这一点上超越 rag
- 从生产力角度来说,目前大参数量 LM 解决领域一些问题之后,下一步追求的就是怎么用小的,当人力 sft 成本远低于算力成本时候,肯定就会走 sft,不同阶段不同选择
- 构建 Agent 的过程中记忆部分
- 目前的 agent 通用架构都有涉及到记忆部分,上下文越来越长,那么是否可以把所有的对话都输入到 token 中?
- 可能目前不这样做的理由就是对话记忆的意图变化,会稀疏掉最新的意图
- 有助于回忆历史,但是对于回忆带来的事件性动作无益处,例如:我今天做了一个热玛吉。这个回忆是程序性的,但是我做了热玛吉就会关注术后相关的内容。这部分由回忆引起的事件性动作是需要结合特定逻辑能力实现的。
- 当前阻止了我们把所有知识和对话一股脑给到大模型的理由
- 费用,目前还是 token 计费,可预见性的当算力资源充足的时候,以次数计费也会出现