客户端
今天收到了 comfyui 桌面版的下载邮件了,突然发现人家开源了。
GitHub 地址: https://github.com/Comfy-Org/desktop 官方指南: https://comfyorg.notion.site/ComfyUI-Desktop-User-Guide-1146d73d365080a49058e8d629772f0a 申请地址: https://www.comfy.org/waitlist
实际界面体验如下:
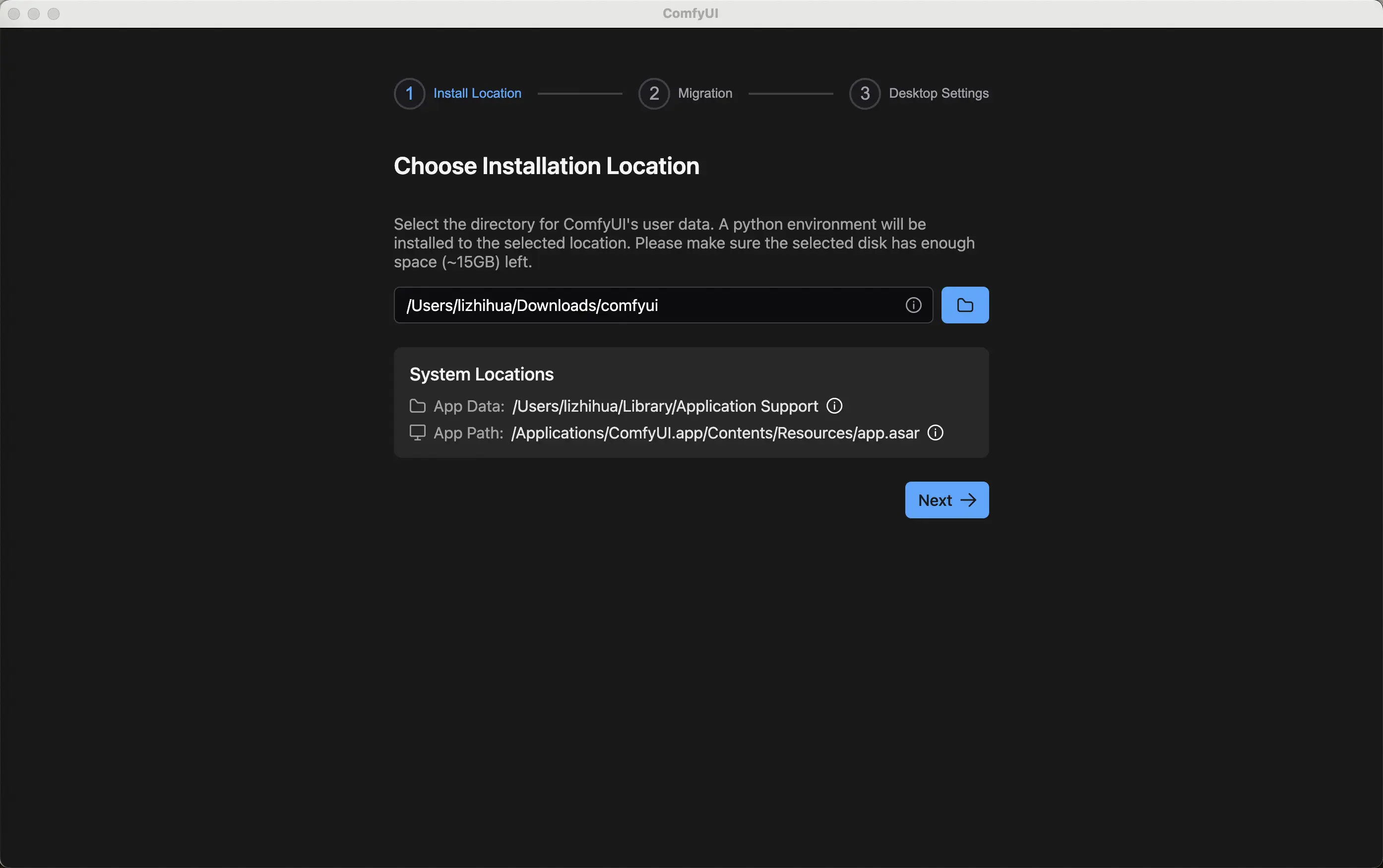
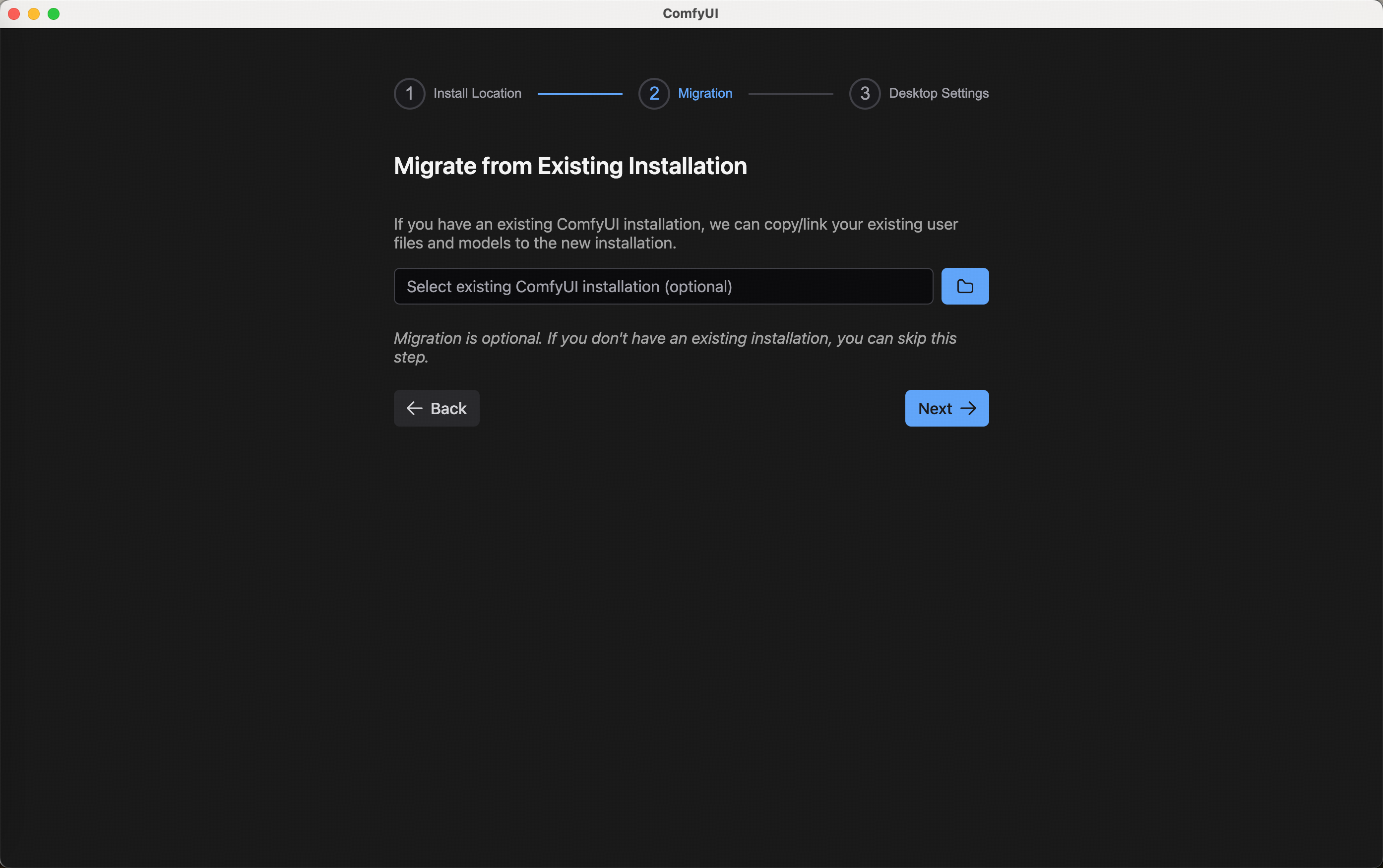
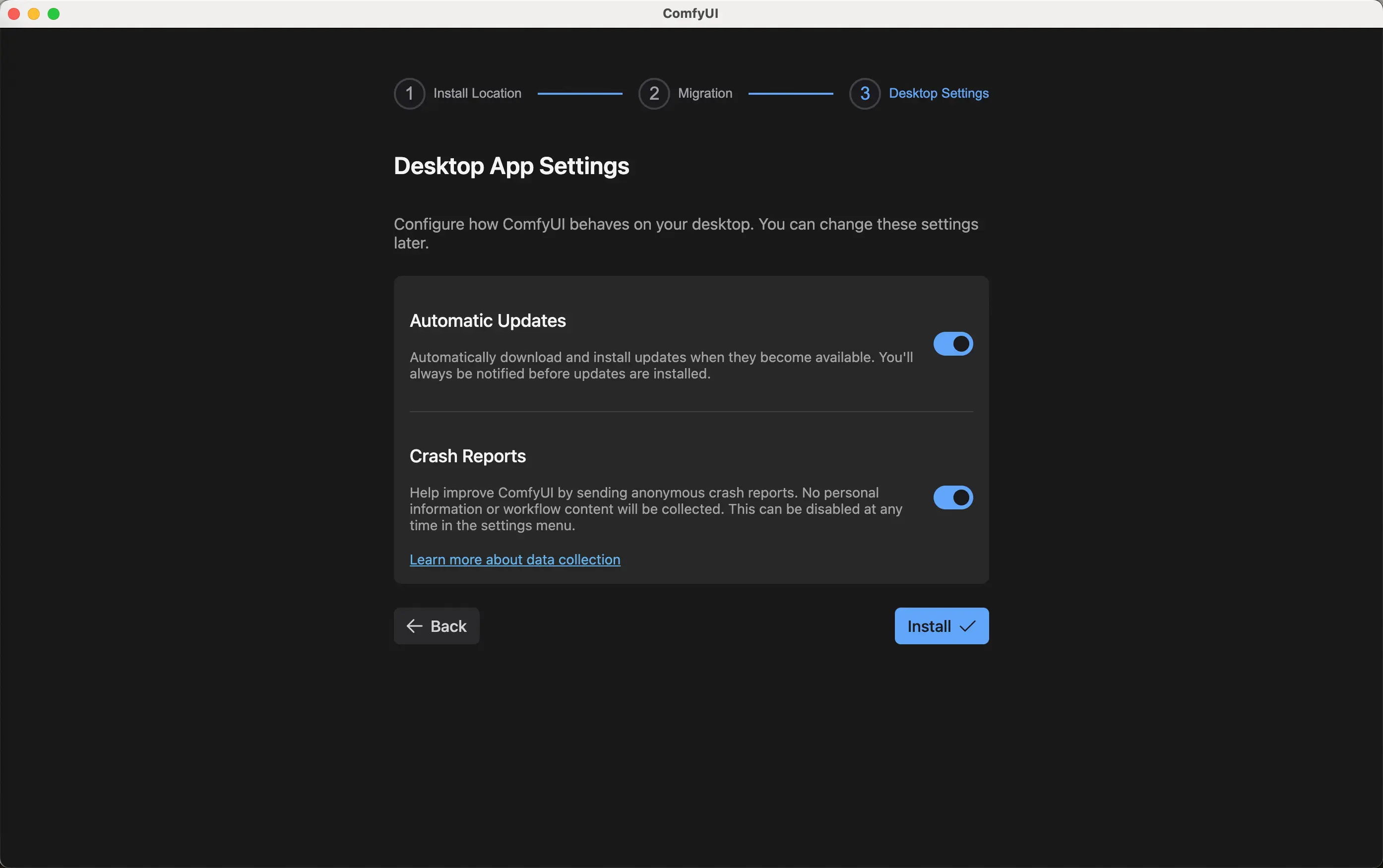
自行下载依赖以及包

默认文生图工作流

文件夹内容

附带一下最近学习的一点小笔记(持续更新)
比较好的自学网站: https://www.comflowy.com/zh-CN/docs
比较好的课程可以去 B 站搜小王子
云安装
下载comfyui
!git clone https://github.com/comfyanonymous/ComfyUI.git
安装管理插件包
!cd ComfyUI/custom_nodes && git clone https://github.com/ltdrdata/ComfyUI-Manager.git
!cd ComfyUI/custom_nodes && git clone https://github.com/AIrjen/OneButtonPrompt.git
!cd ComfyUI/custom_nodes && git clone https://github.com/pythongosssss/ComfyUI-Custom-Scripts.git
下载扩散模型
!wget -P ./ComfyUI/models/checkpoints https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/ChilloutMix-ni-fp16.safetensors
!wget -P ./ComfyUI/models/vae https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/vae-ft-mse-840000-ema-pruned.ckpt
启动comfyui服务
!cd ./ComfyUI/ && python main.py
工作流
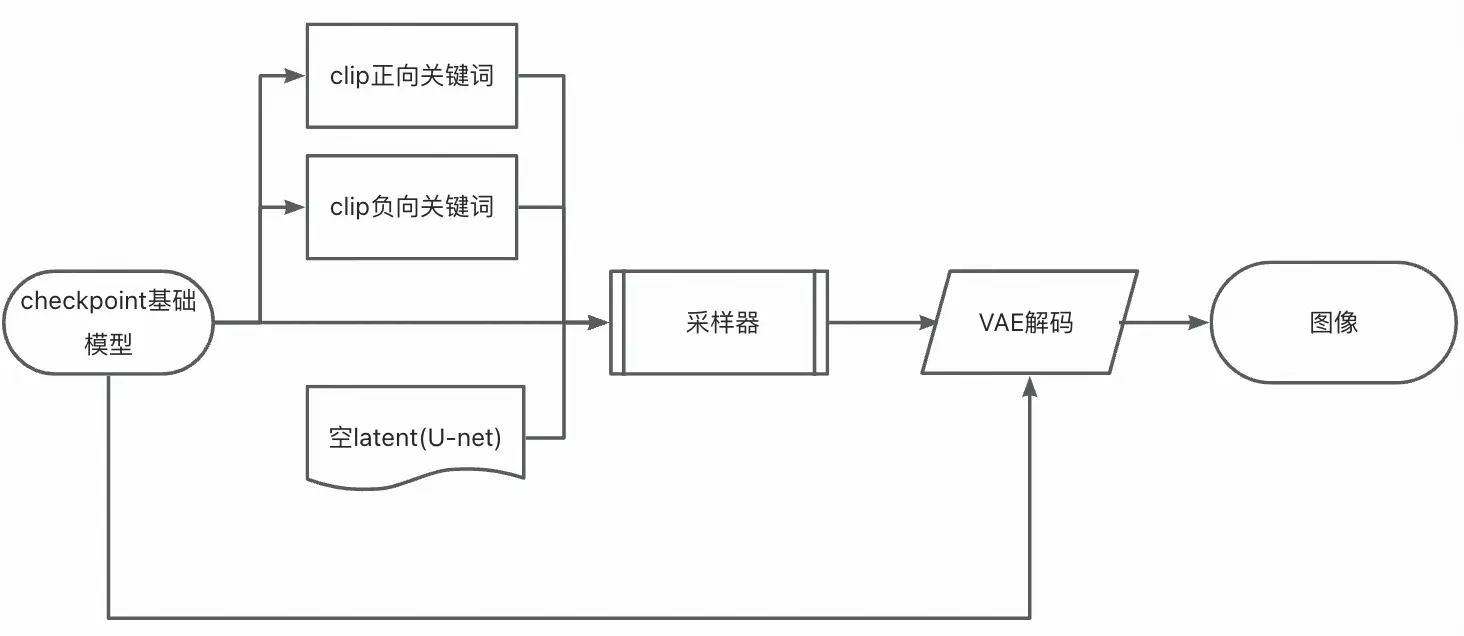
- 基础
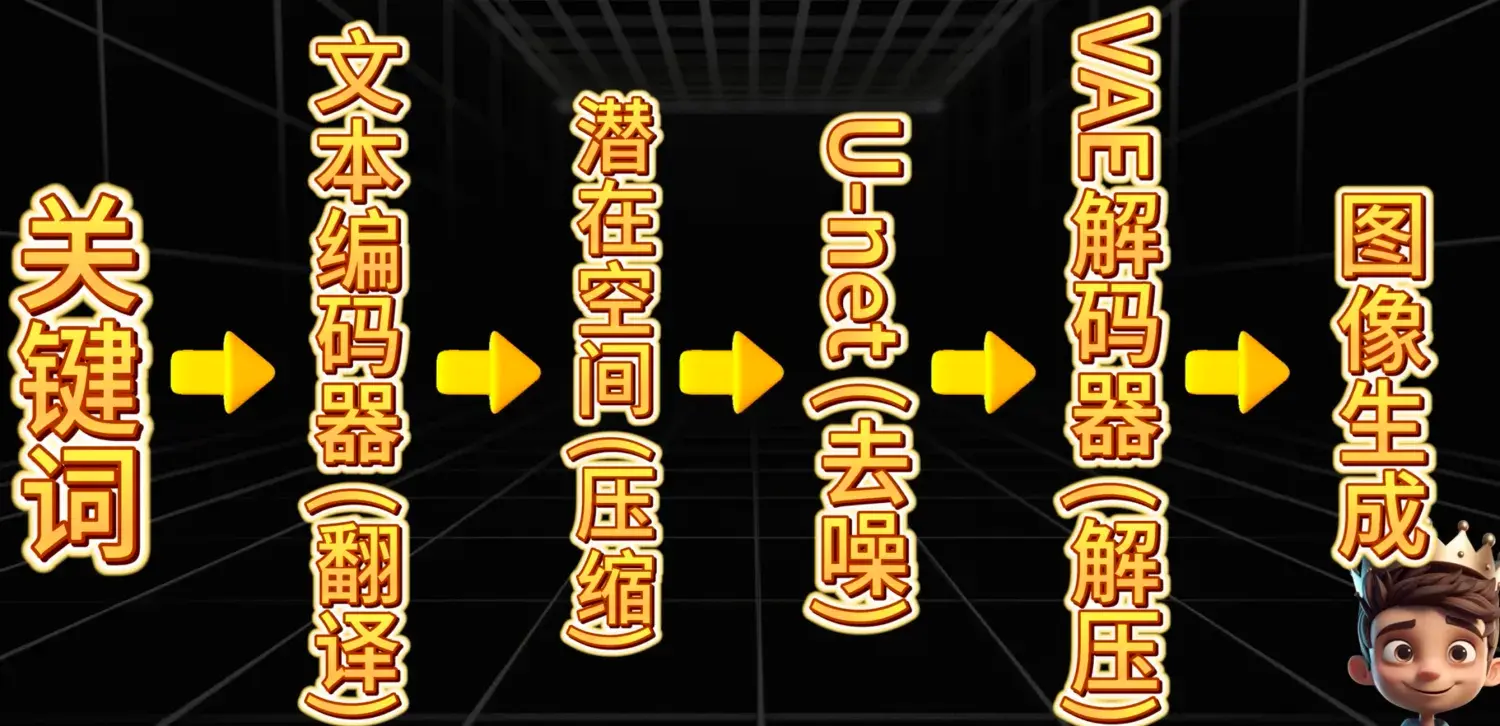
- 最基础的文生图

实用Tip&工具
- 操作按钮
- 修改语言:ACLTranslation-langualge
- 自动补全关键词:Text Autocomplete: enabled
- Ctrl 选中,Ctrl+G 创建组,Ctrl+M 隐藏
- ComfyUI-Detail-Daemon 可以大幅增加 FLUX 生成图像的细节。
- Quick connection 方便的链接节点以及节点展示不遮挡
- 提示词自动化书写技巧
基础
- 精准表达意图,长度最好保持在 75 个 token(或约 60 个字)以内
- 越重要的词放在靠前的位置
- 使用逗号分隔,输入 (keyword:weight) 方式来控制关键词的权重,比如 (hight building: 1.2 ) 就意味着 hight building 的权重变高
模板
Subject:因为主体是最重要的,所以主体一般会放在首位。
Environment:环境包含:
- 主体周围的环境,比如说「在一片森林里」、「在一片草地上」等等。
- 灯光,比如「闪电」、「月光」等等。
- 天气,比如「下雨」、「下雪」等等。
Medium:媒介可以是图片的拍摄媒介,如「相机」,亦或者承载的媒介,比如「油画」。
Style:可以用 4W 记忆:
- When:什么年代的风格?
- Who:你想要谁的风格?(人或组织)
- What:什么艺术类型的风格?或者艺术运动的风格?
- Where:什么国家的风格?
图生文反推
自动写反推
节点预设
SDXL风格预设
名词释义
- CFGscale:关键词与图片的相关性,越高与关键词越贴切,建议3-9之间,使用模型建议即可
- 采样器:Eular_ancestral 遇事不决就用;dpmpp_2m_sde 比较百搭
- 调度器:normal,限行均速降噪;karras,刚开始降噪比较缓慢,中间增速,最后又缓慢;
- 降噪:重绘幅度,文生图的时候默认保持1。
- 默认负向关键词:embedding: easy negative
提示词书写方法与技巧
图生文提示词反推插件:WD14Tagger
反向提示词自动填写插件:one button prompt (auto negative)
自动风格化提示词:sdxl_prompt_styler
超强反推插件:JoyCaption2
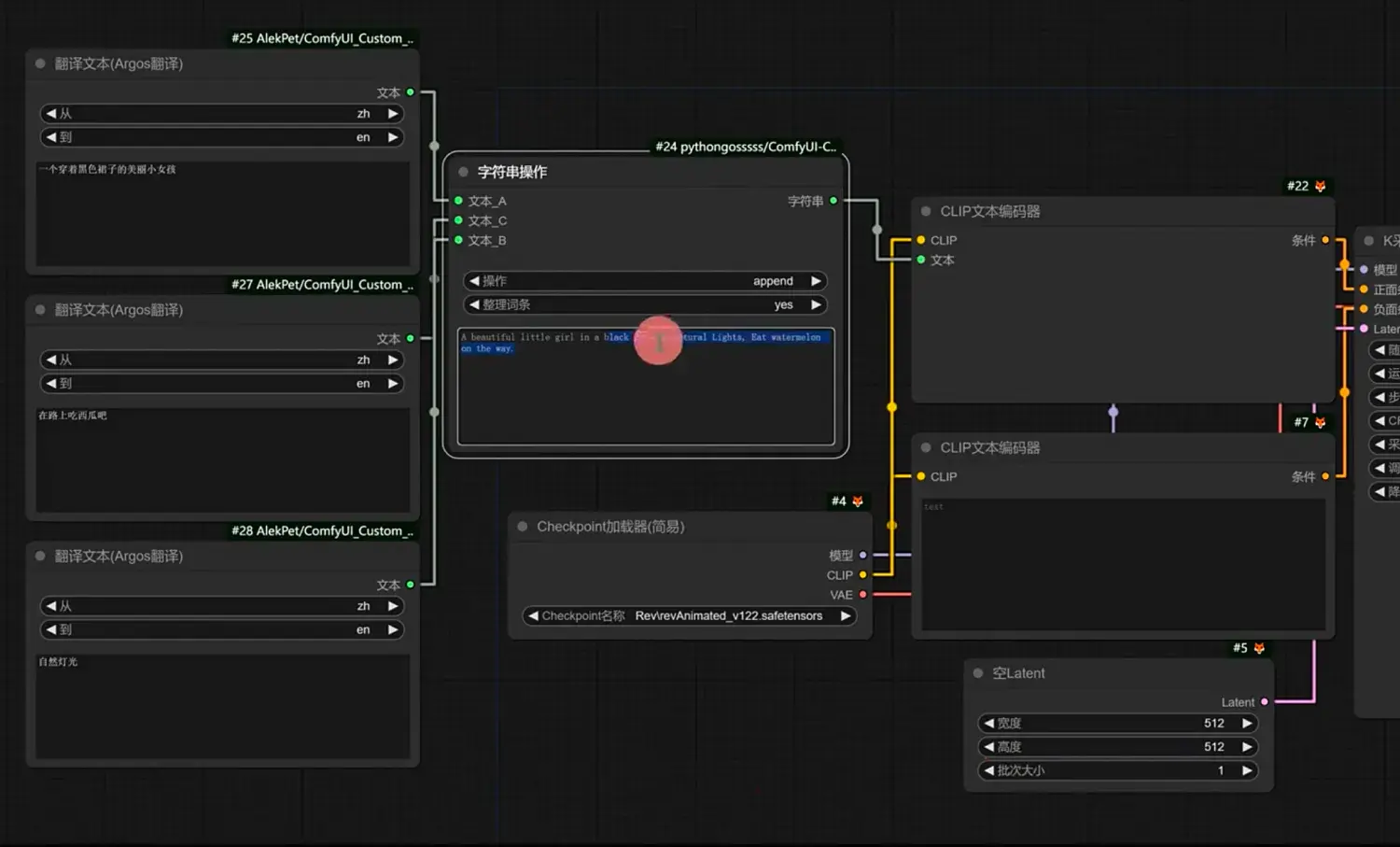
中文提示词书写
插件:AlekPet 包含6个节点
- Argos:纯本地翻译不需要网络
- google translate:需要网络+魔法(不好用)
- Clip 翻译高级:需要网络,可切换不同翻译API
ComfyUI必备工作流和模型网站+如何解决图像颜色发灰问题
- Http://openart.ai
- Http://liblib.ai 中国最大
- 可以在线生图,但是所有的节点都是内置好的,不能自己添加
- Http://civitai.com 全球最大最全
- Http://comfy.icu 调用平台工作流直接生成,并可以直接在线调整
Ps:
- 各个模型最好做文件夹分类,文件夹名称使用英文
- Checkpoint 高级(pysss), 可以直接展示文件夹,模型信息和预览图
- 如果图像发灰需要单独加载一个 vae 模型,不过目前最新的模型基本上都自带 vae 解码
图生图基础工作流搭建+人物转绘+Controlnet 线稿应用
简单转绘
- 使用节点:加载图像->vae 编码->复制 latent 批次->K 采样器

- 人物转绘:正向关键词填写人物特征
- 降噪:控制重绘幅度,越高就跟原图越不像
- 改变图像大小:加载图像->图像缩放节点->vae 编码->复制 latent 批次->K 采样器
- 图像对比:节点 rgthree ,放在 vae 解码之后,替换预览即可
- 生成图之后播放声音:节点 Custom Scripts
Controlnet
- 大模型什么版本就选择什么版本的 controlnet
- 使用节点:

节点整合实现高效工作流
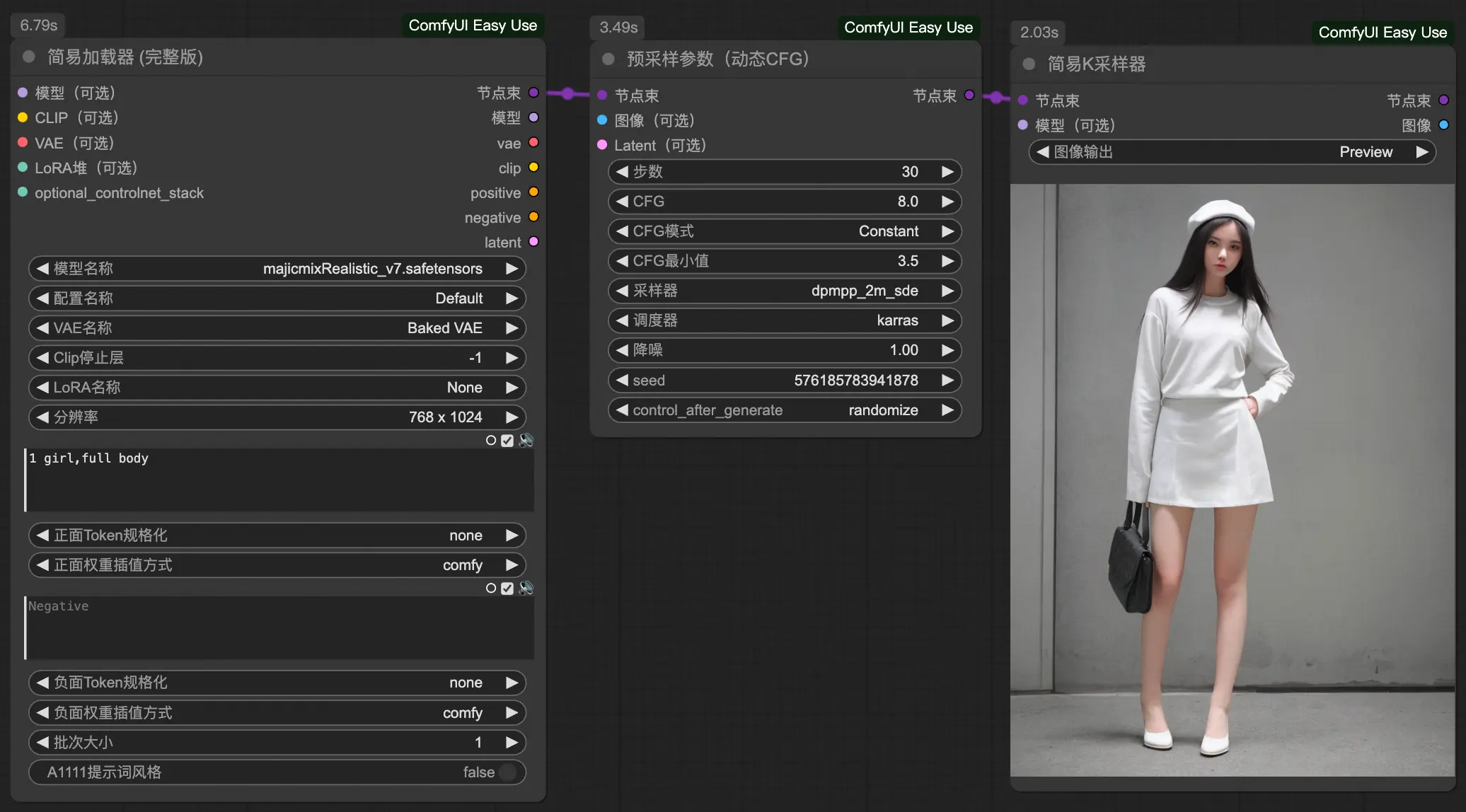
节点整合最简文生图
- Efficiency Node
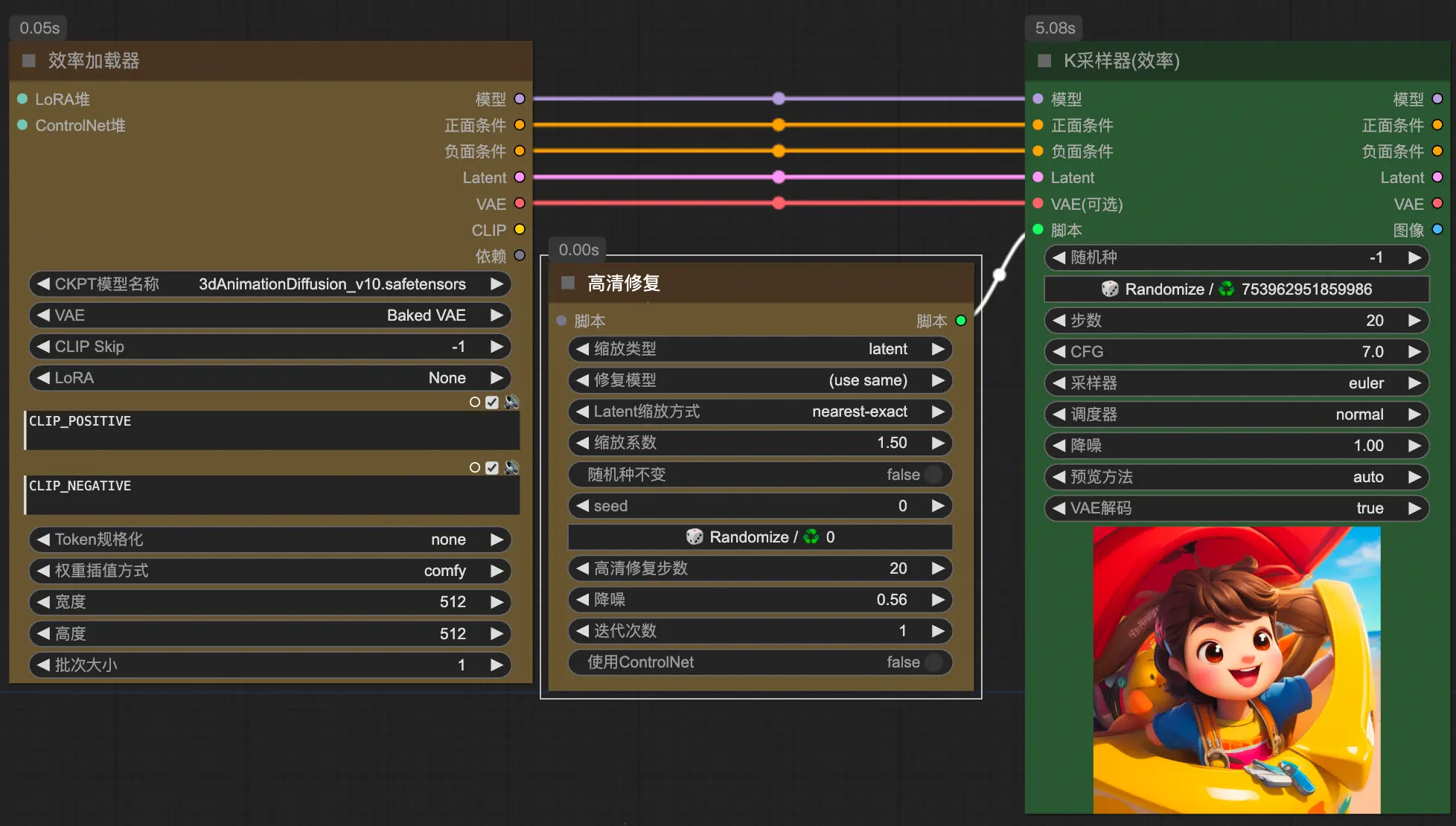
- Easy Use
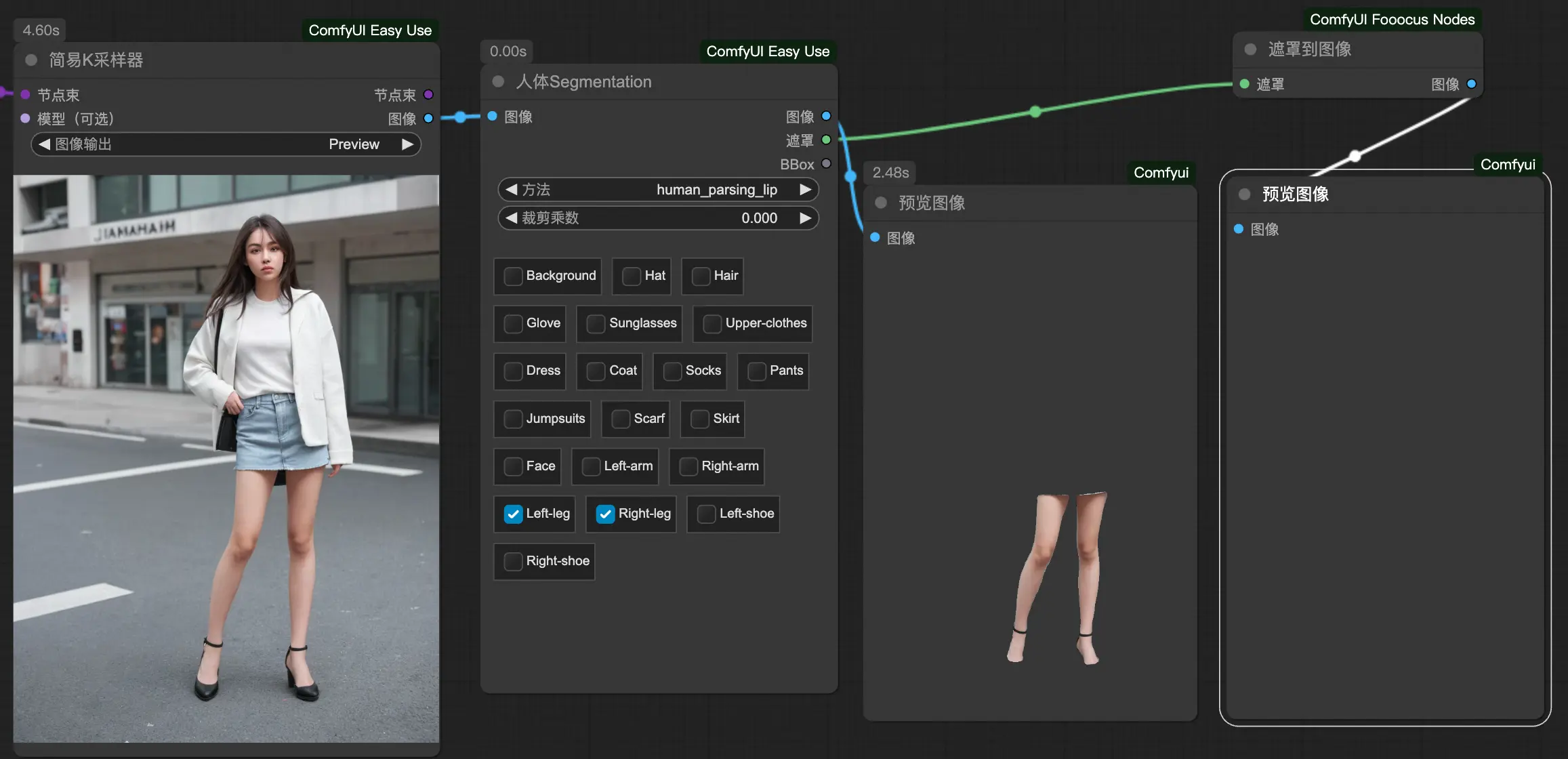
- Segmentation 抠图和蒙版
实时渲染出图 Mixlab 与 Turbo、Lightning、LCM 模型
Turbo 模型特点:仅需要 4-8 步
Lightning 参数:
- 尺寸由模型版本决定 SDXL 1024*1024
- 步数:4-8
- CFG:1-2
- 采样器调度器使用作者推荐
LCM 特点:Low Compute Model
- 对核心算法进行了深度优化的微调模型可以大幅度减少生成图的计算数量
实时渲染节点:(效果一般)
- Mixlab

ComfyUI 加速出图(TensorRT)
不支持 controlnet 模型
与 turbo、lightning、LCM 区别
- 以上三个是通过优化和更改模型架构来实现快速生图
- TensorRT 是不改变原有模型的架构,而是去优化显卡的计算效率,同时最大化的利用显卡的性能来提升出图速度
包含三个节点

- Filename_prefix 是文件的名称尽量不要动!
- 训练好的模型在:根目录-output-tensorrt
- 模型命名规则(必须英文且没有空格):模型种类_模型版本_模型简称_宽_高_batch size_静态/动态
- 例如:3D_XL_Rev_768_768_1_static
连接方式:

局部裁剪、高效智能抠图与局部分割
- 局部裁剪

- 智能抠图:自动识别主体
- Inspyrenet:效果最好
- Threshold 范围 0-1,越高越精细,越干净,但是不要调到 1
- Segment anything:做局部语义分割
- Birefnet-zho:适合扣多主体,需要配合对应的抠图模型
- Birefnet-hugo:适合单一主体
- Kjnote
- Comfyui Essentials
- layerdiffuse
- 生成图片的时候,会简化背景突出主体

- Inspyrenet:效果最好

面部细节修复与更改
- 多出现任务在远景、广角的时候,尤其是1.5版本的模型
- 扩展:impact pack 节点:面部细化
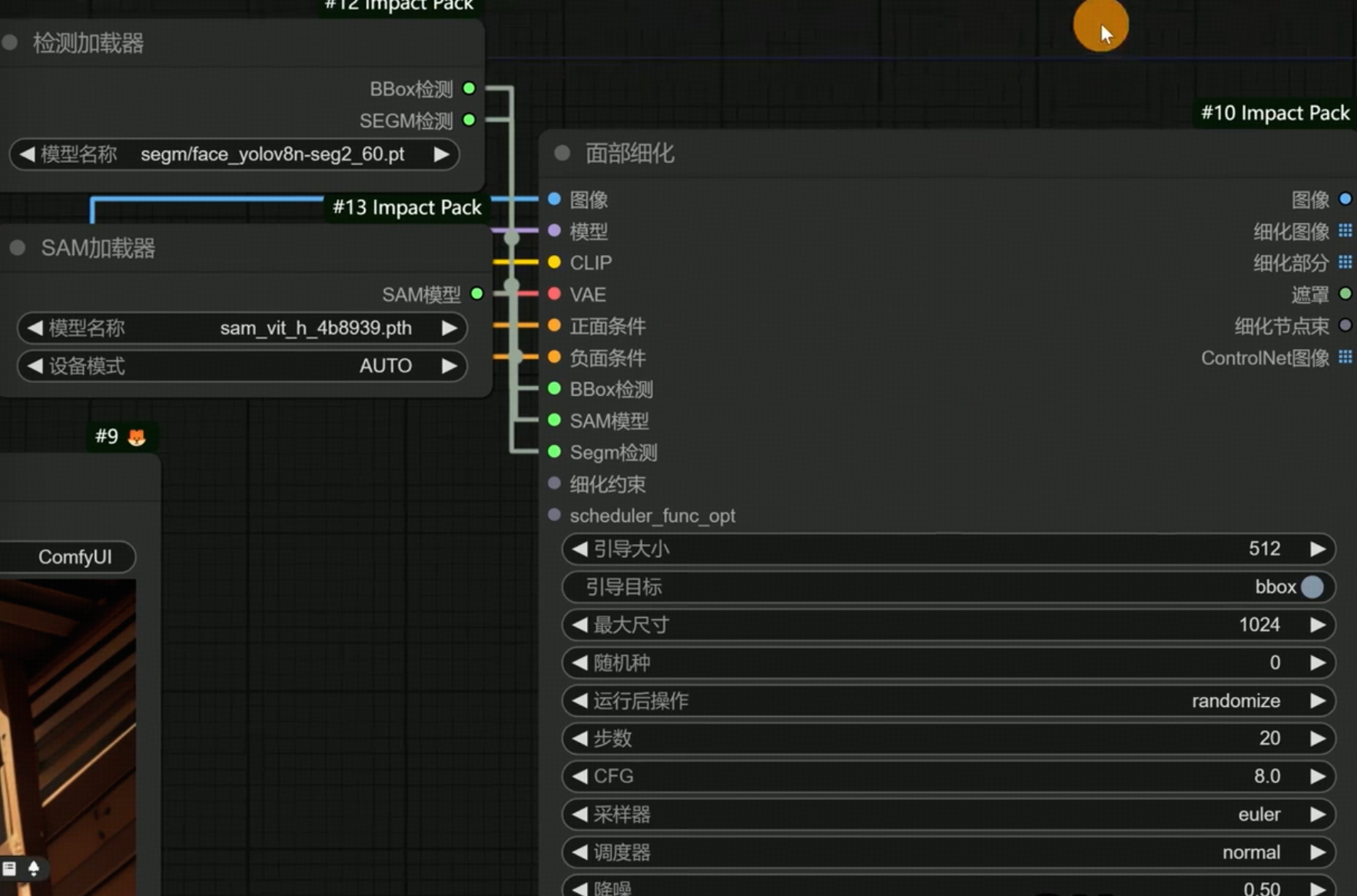
BBox检测连接 检测加载器(Segment anything 包里面的)
- 通过指定模型以方格的方式识别局部修复区域
- 面部修复使用 bbox/face_yolov8m.pt
- 使用非segm不需要连接segm节点
SAM 连接 SAM加载器
- 模型选择 sam_vit_h_4b8939.pth
参数
- 引导大小:重绘区域的像素 数值越高越精细,当画面存在多个面部或人物面部非常远的时候,可以适当调高这个值
- 最大尺寸:当你的出图分辨率达到1024这个设置值的时候就不会开启重绘,如果想要超过1024也重绘就需要开启强制重绘
- 降噪:越高重绘幅度越大,修复越好
- 羽化:BBox是以方块的模式,羽化就是使这个方块的边角更柔和
- BBox阈值:检测重绘精细度,数值越高检测越马虎;当图片有多面部并且人物很远时,数值可以调低一些增加辨识度
- 膨胀值:给BBox的方块做圆角,会与环境更加融合
- BBox剪裁系数:头像部分与环境的裁切大小,尽量不动,面部还是需要与环境有一些互动的
- SAM检测提示:center以中心为基准
- 关键词:可以修改面部的表情年龄等
- cycle:修复轮数
- impaint model:当你的大模型是专门的局部重绘模型再开启
- noise_mask_feather:也是羽化的意思,默认不用处理
FLUX模型安装教学与测评分析
https://huggingface.co/black-forest-labs/FLUX.1-dev/tree/main
vae模型:ae.sft
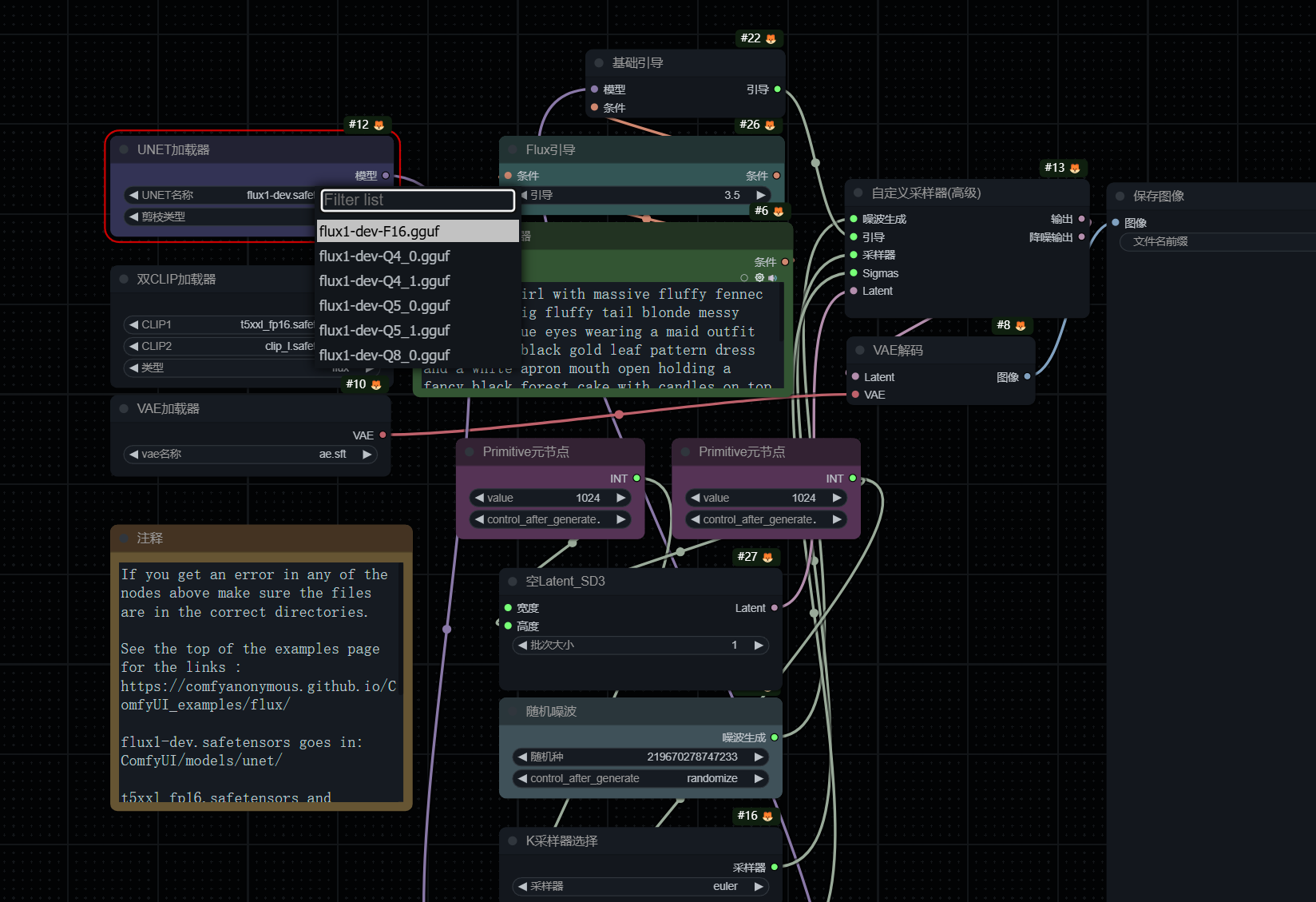
原模型:放在unet flux1-dev.sft
- PS: UNET加载器检测不到flux模型,只能检测到gguf模型文件,是因为 ComfyUI-Flow-Control 这个插件导致的,卸载之后重启就可以了,可以参照这个issue https://github.com/city96/ComfyUI-GGUF/issues/179
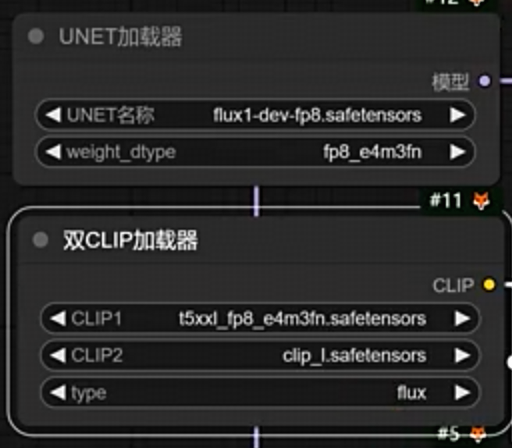
fp8版本生图速度更快,质量差异不大 https://huggingface.co/Kijai/flux-fp8/tree/main
clip 模型:和SD3模型类似需要配合 https://huggingface.co/stabilityai/stable-diffusion-3-medium/tree/main/text_encoders
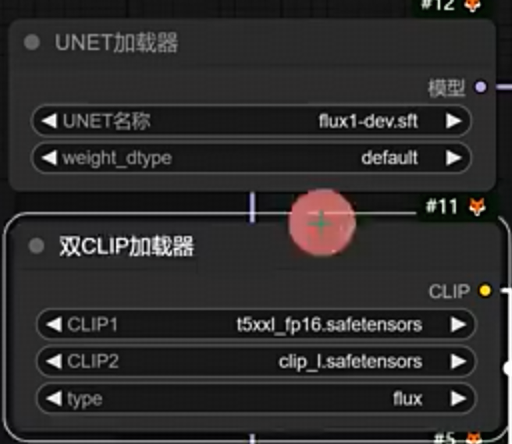
unet加载器
- 原模型 weight_dtype 选择默认default
- 双clip加载器 t5xxl_fp16 和 clip_l
- fp8 需要对应的修改
宽高比优化:随意尺寸都支持;
无需负面提示词与CFG scale,尽可能把你的关键词写的非常准确
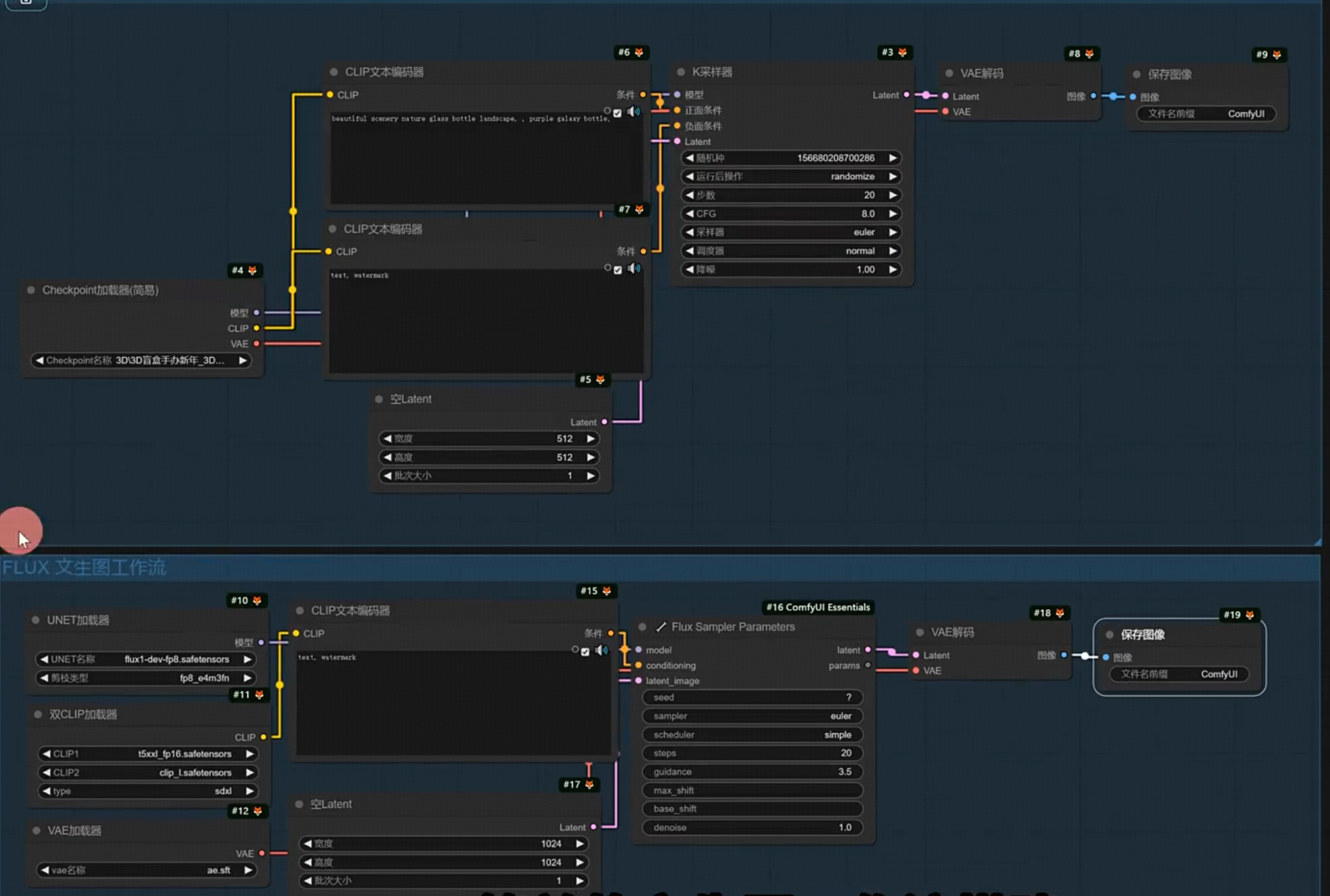
FLUX文生图 图生图 局部重绘 高清放大 lora全生态讲解
1.搭建flux生态所需:模型、vae、clip、lora、controlnet、节点包等
模型、vae等参考以上,负面clip不需要(如果要链接节点就建一个空节点)
NF4小知识:Next-Gen Flux Model,在尽可能保证细节的基础上,最大程度还原原模型的效果,速度提升4倍,显存要求降低4倍;整合了clip和vae,需要放在checkpoints;要单独的加载器
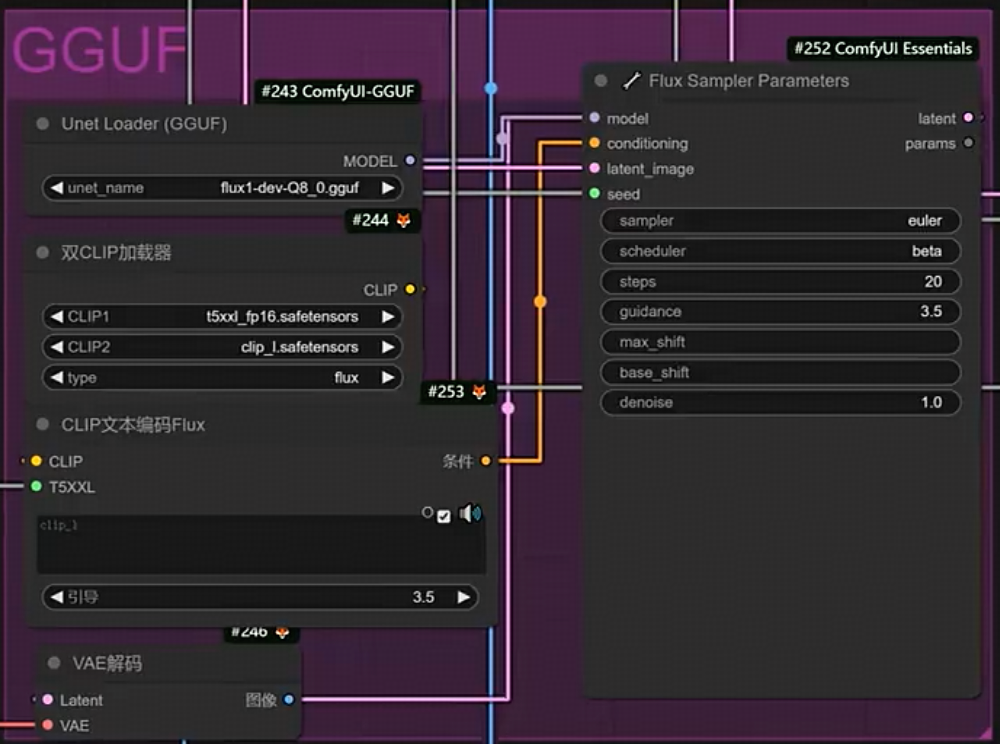
GGUF:GPT-Generated Unified Format,大语言模型训练LLama.cpp框架中的一种文件格式,可以在任何大模型统一框架的基础上简化模型的处理;需要放在checkpoints;要单独的加载器
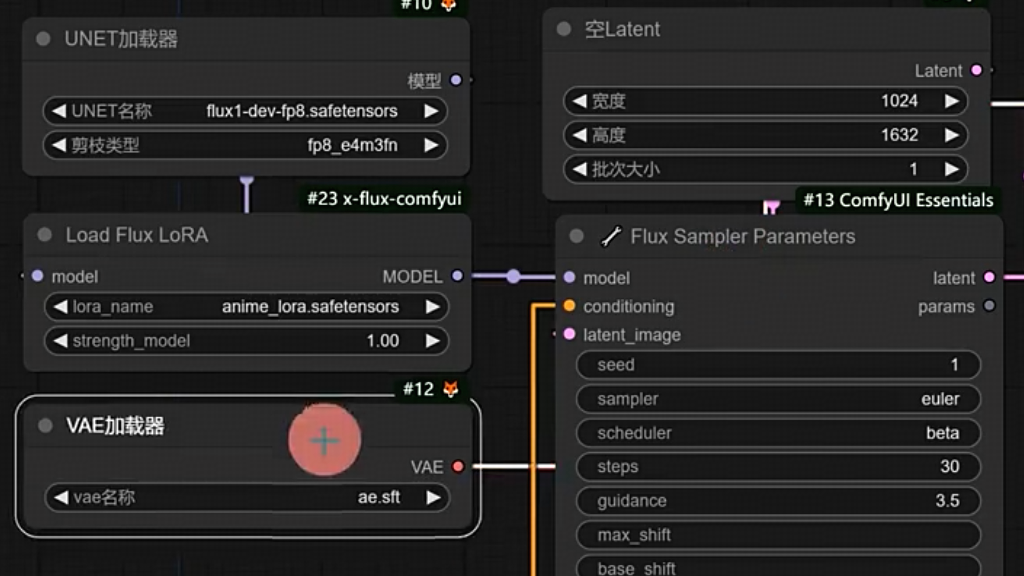
扩展节点包:https://github.com/XLabs-AI/x-flux-comfyui 放入custom nodes
lora模型:https://huggingface.co/XLabs-AI/flux-lora-collection/tree/main
- 带有comfy_converted 代表可以被普通的lora加载器识别,可以直接放入loras 目录
- 另外的需要放入 models/xlabs/loras 文件夹才能被扩展节点包识别
- 加载节点:load flux lora 或者普通的 load lora,位置放在unet模型和k采样器之间
controlnet: https://huggingface.co/XLabs-AI/flux-controlnet-collections/tree/main
- 放入 models/xlabs/controlnets
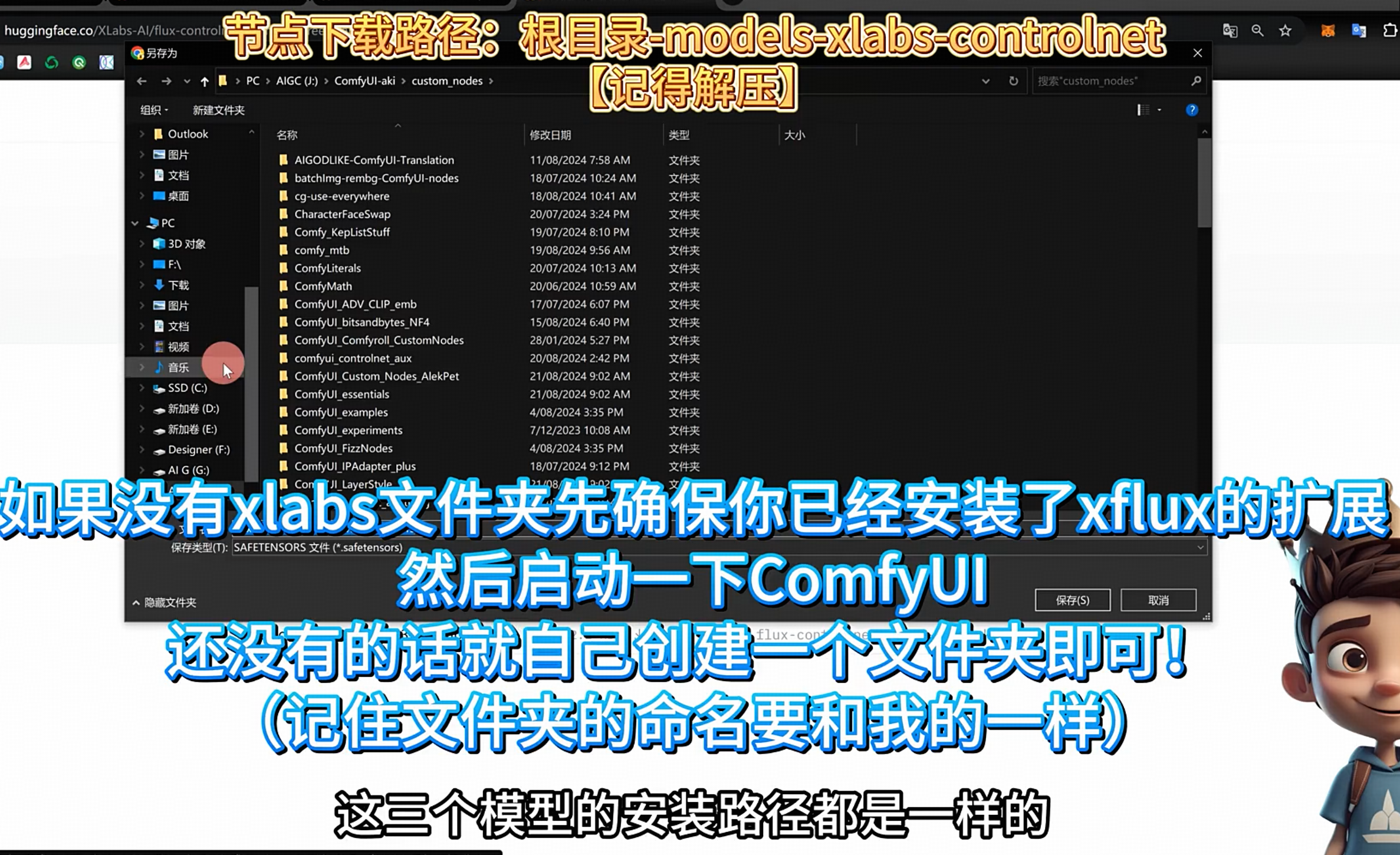
- 放入 models/xlabs/controlnets
在liblib上找flux:筛选基础底模F.1
2.flux 文生图与最佳采样器
单独的k采样器: flux sampler parameter,在comfyui essentials 扩展里面
- 官方推荐:euler+simple
- 小王子推荐:euler+Beta
可尝试:uni_pc_bh2 + simple 或者 ipdmn + simple
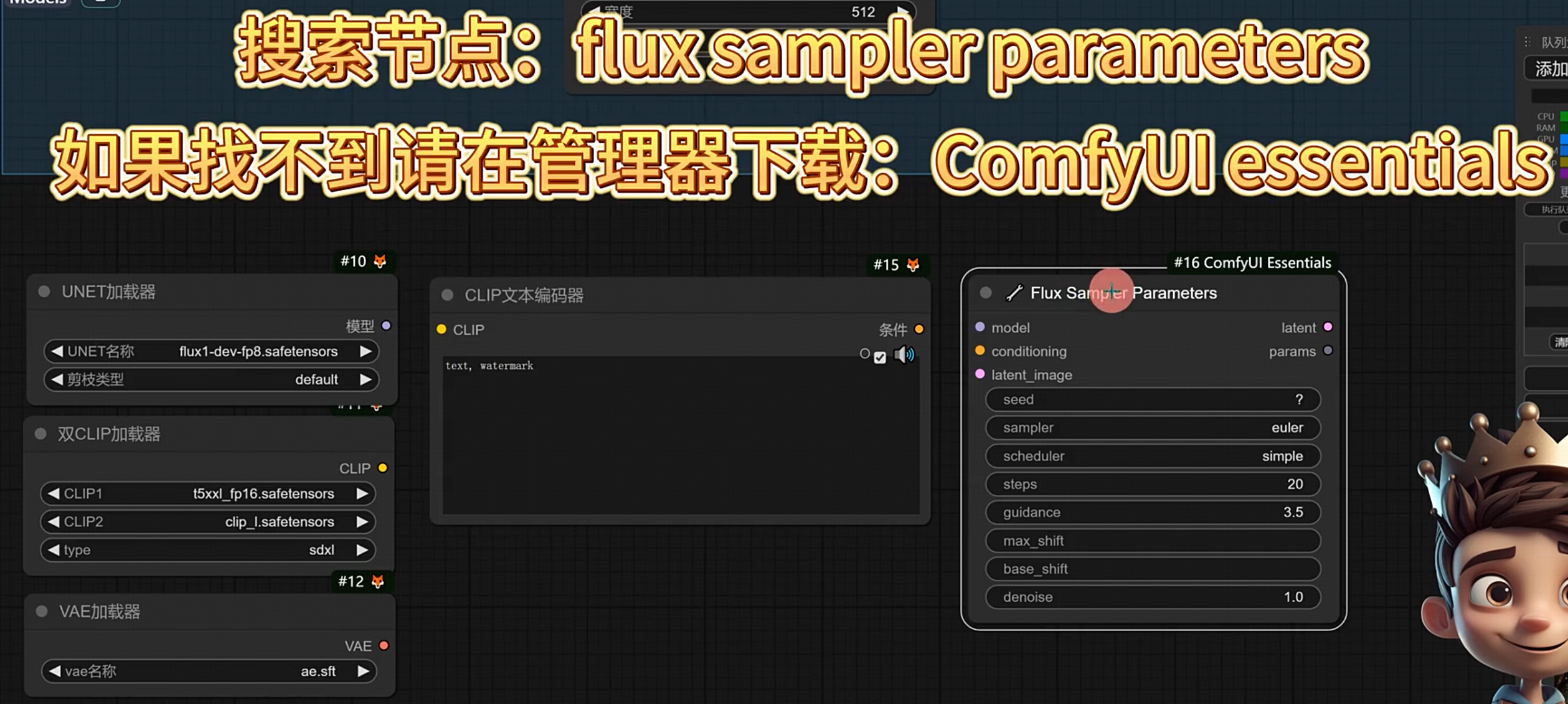
guidance:是CFG 里面的G,控制提示词的相关性;
- 官方推荐3.5,建议2-5之间
- =2的时候艺术发挥空间更大艺术效果更浓,>5的时候画面对比度会强烈
- <3画面会偏写实,>3画面会偏动漫,如果目的要做写实建议2-3,如果目的要做非写实建议3-4.5
生图技巧:先拿GGUF跑到满意,然后拿FP16dev用相同的参数生成更细节的图,之后在做高清化处理
与基础的区别
3.flux 高清放大
节点:Ultimate SD upscale
SD放大
- 放大模型:使用放大模型加载器 4x-UltraSharp
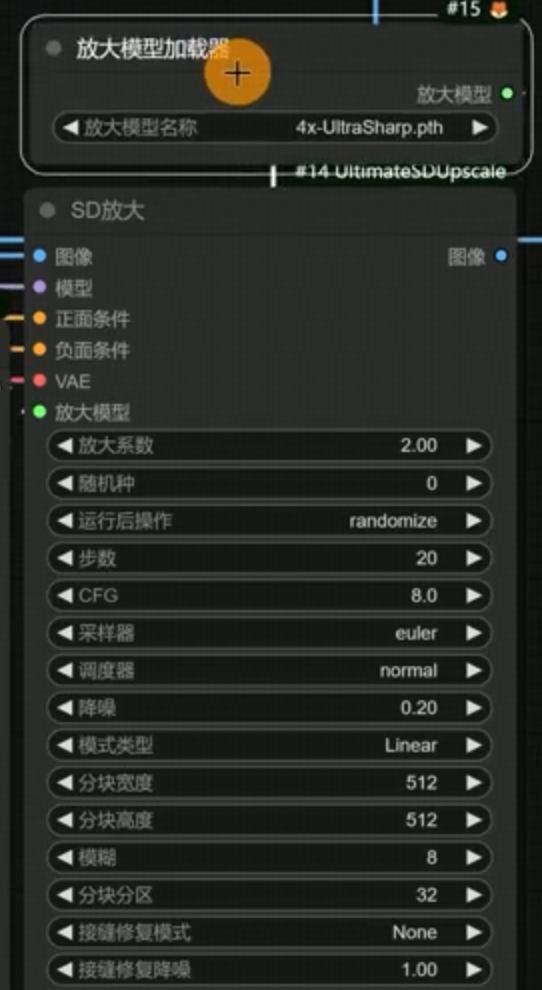
- SD不放大:没有放大模型连接加载,用来做二次采样
- 记住CFGScale =1,当使用flux模型的时候不得不调整CFGScale 就调整为1
采样器、调度器: Euler normal
降噪:不要太高,太高就和图片不像了,建议改到0.1-0.2之间;如果需要放大的同时增加更多的细节,调整到0.35-0.5;
原理:把整张图片根据根据你的分块宽度和高度,切片为不同数量的方格图,逐一去渲染
模式类型:
- 直线:按照从左到右,从上到下的顺序逐步渲染
- chess:按照不规则交叉渲染
- none:直接放大,不做分块处理,和 图像通过模型放大节点效果一样
分块宽度、高度:
- 原图1024,放大到2048分块在512,放大到4096分块在1024
模糊、分块分区:尽可能往高处设置,保证8的倍数,64等
接缝修复模式:如果出来的图片没有缝隙,不建议打开,会再次重绘一边图像有可能会导致变化
- none:不会给图片带来任何影响
- half tile:修复效果最好,但是生图速度最久
- 变化的强度取决于:接缝修复降噪、接缝修复宽度、接缝修复模糊、接缝修复分区
4.flux 图生图
- 增加加载图像和vae编码即可
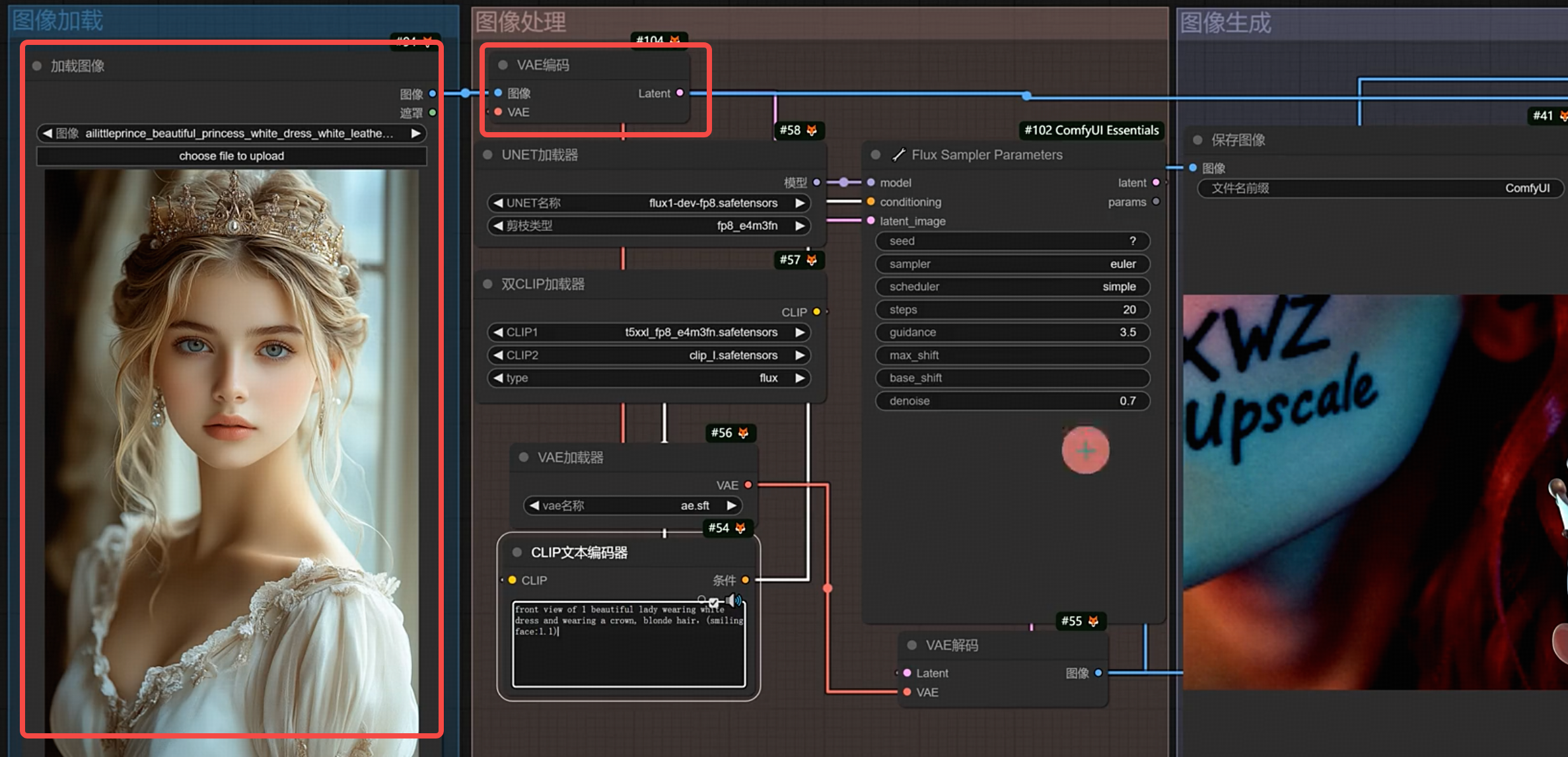
- 图生图最关键的参数:提示词和 denoice(重绘幅度,数值越低和原图越相似,数值越高和原图越不同)
5.flux 局部重绘
- 节点:differential diffusion(差异扩散) 可以逐步改善图像质量并生成细节更丰富;链接到模型和模型之间
- 节点:gaussian blur mask(高斯模糊)专门优化蒙版边缘衔接的节点;链接到原始图像的遮罩
- 大小/sigma,数值越高蒙版越模糊
- 节点:InpaintModelConditioning(内补模型条件)内置vae编码,所以一开始图像的vae编码可以去掉;
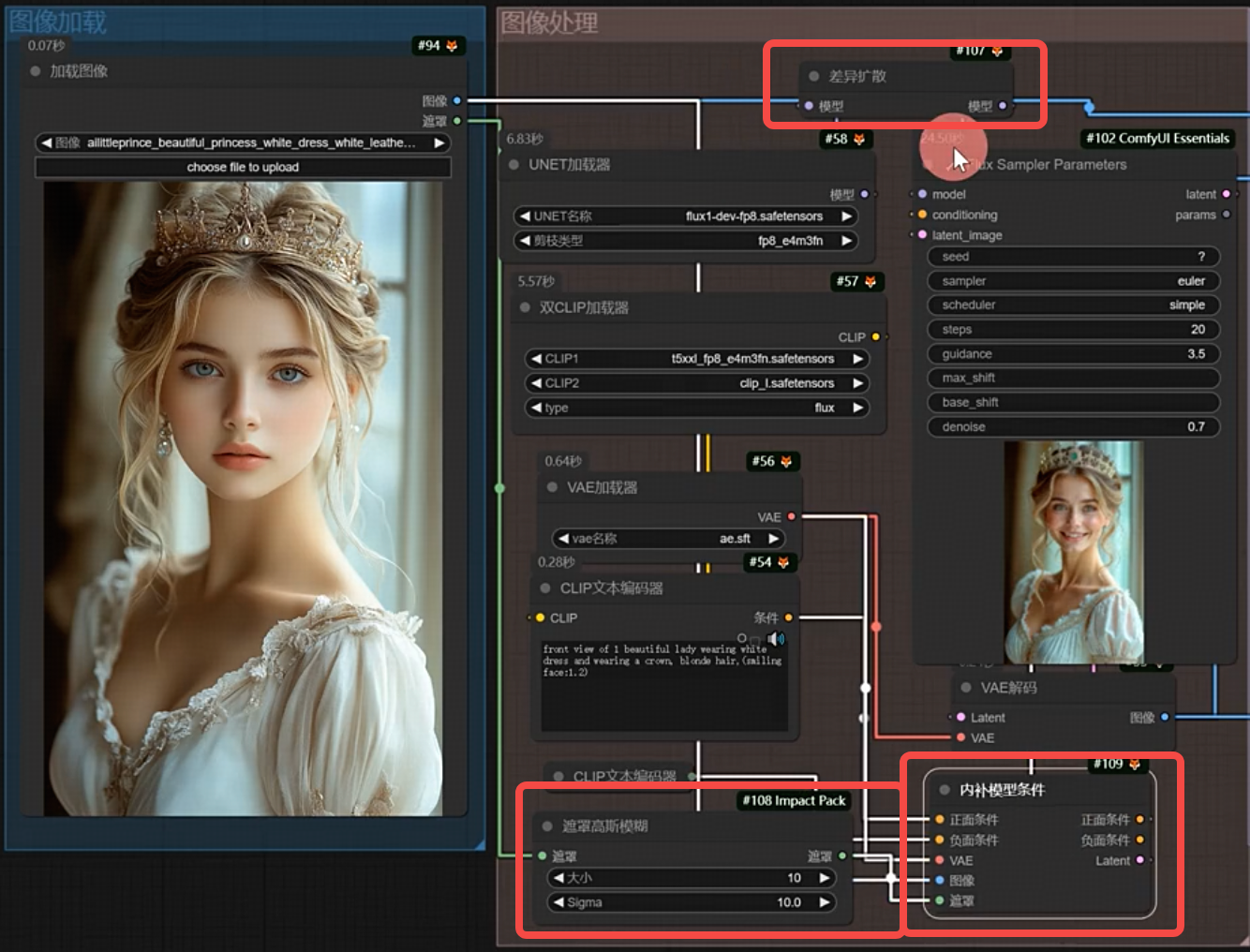
- 使用:右键加载的图像->在遮罩编辑器中打开,选择要修改的区域,然后调整denoice
- 可以配合 G-dino语义分割 自动局部重绘,无需手动描选遮罩区域。
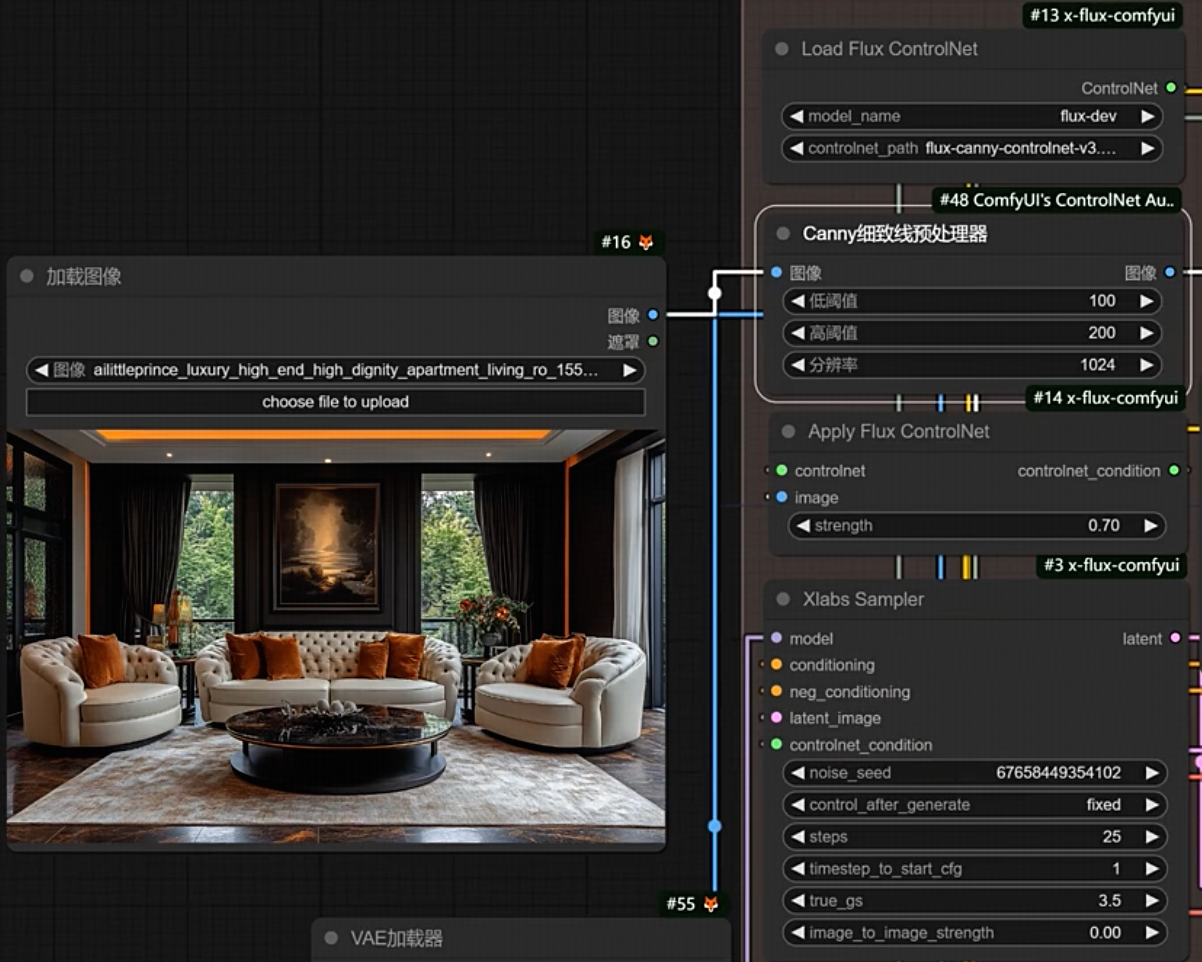
6.flux controlnet
- 节点:load Flux ControlNet,加载模型
- 节点:在aux扩展包里面,包括:canny edge、Midas Depth map、Hed soft edge lines

- 节点:Apply flux ControlNet
- 节点:Xlabs sampler
- 以上为Xlabs的controlnet,还有一个Union,但是效果很差 https://huggingface.co/InstantX/FLUX.1-dev-Controlnet-Union
4K高清放大画面细节修复扩展详解
- 之前提到过 高清修复 和 flux 高清放大
- 节点:图像通过模型放大
- 放大模型加载器:4x-UltraSharp;推荐这个比较真实,其他会出现磨皮过重的效果
- 如果不想放大4倍
- 扩展:comfyroll Studio 节点:放大图像
- 更好的放大节点:SD Ultimate upscale 详细说明放在 flux 高清放大
ComfyUI 更新
这个更新主要是让用户在 ComfyUI 里对 LoRA 和模型权重进行更灵活的控制,包括利用「蒙版(Masking)」和「时间表(Scheduling)」的方式对它们的影响区域与影响时机进行细分与调控。
简单来说: LoRA 和模型权重的「局部应用」: 以前要对整个图像应用 LoRA 或模型风格,现在可以通过对特定区域(使用蒙版)来局部应用这些权重。这样你可以让一部分图像使用一个风格模型,另一部分使用另一个 LoRA 权重。
LoRA 和模型权重的「分步调节」: 你可以根据生成过程中的不同步骤(扩散的不同时间点)对权重进行调整。比如在早期步骤保持模型原样,中期慢慢引入 LoRA 的风格,后期再加大 LoRA 权重,让最终图像细节和风格更符合你的预期。
简化节点操作: 更新中提供了专门的节点来创建和组合这些「挂钩(Hooks)」和「条件(Conditioning)」,让使用者能更轻松地实现复合式的蒙版与时序控制,而不再需要复杂的绕线和额外节点。
总结新能力:
- 蒙版功能:能将 LoRA 或模型风格只作用在特定图像区域上,轻松实现图像局部风格化。
- 时间轴调度(Scheduling):可在扩散采样的不同阶段动态调整 LoRA 或模型权重,让图像在生成过程中逐步过渡到所需风格。
- 条件节点扩展:新的节点能轻松组合、分配、叠加和定制 Conditioning,既可手动又可自动为不同部分或不同阶段添加 LoRA 和模型权重。
通过这次更新,你的模型控制会更加精细化,可以同时在空间与时间两个维度对风格和特性进行动态调节,从而获得更灵活、更高级的生成结果。