GCC 进化史
API 层面调用 > RPA 固定工作流 > 视觉模型推理
API 层面:基本不可能哈哈,能做也是像支小宝这种,大厂直接入场。第三方开发者指望微信、支付宝等软件开放 API 基本不现实。当然也有部分开放的 API, 大概能实现的场景和 OpenAI 之前演示的差不多,是有很大局限的。
RPA 固定流程:类似影刀等。内部小 team 也一直在研究 RPA 的流程(Sonic 云真机)针对小红书等大流量平台,做起号、截留评论等。RPA 确实稳定,但是不灵活,兼容性较差。
视觉模型推理:荣耀手机、智谱的 AutoGLM,我理解是 AI 对 RPA 的升级版。通过手机系统级别的 无障碍服务(AccessibilityService) 和 OCR 提供视觉推理与操作。
GCC 概念
以下为 AIPM 技能树文档整理有关 GCC 的截图:

我认为的 GCC = LLM 分析 LUI 输入形成拟人化流程(大脑) + 界面内容识别模型(眼) + 多 Agent 判别(Tools 调用)+ 最终操作程序(手)
画个简图↓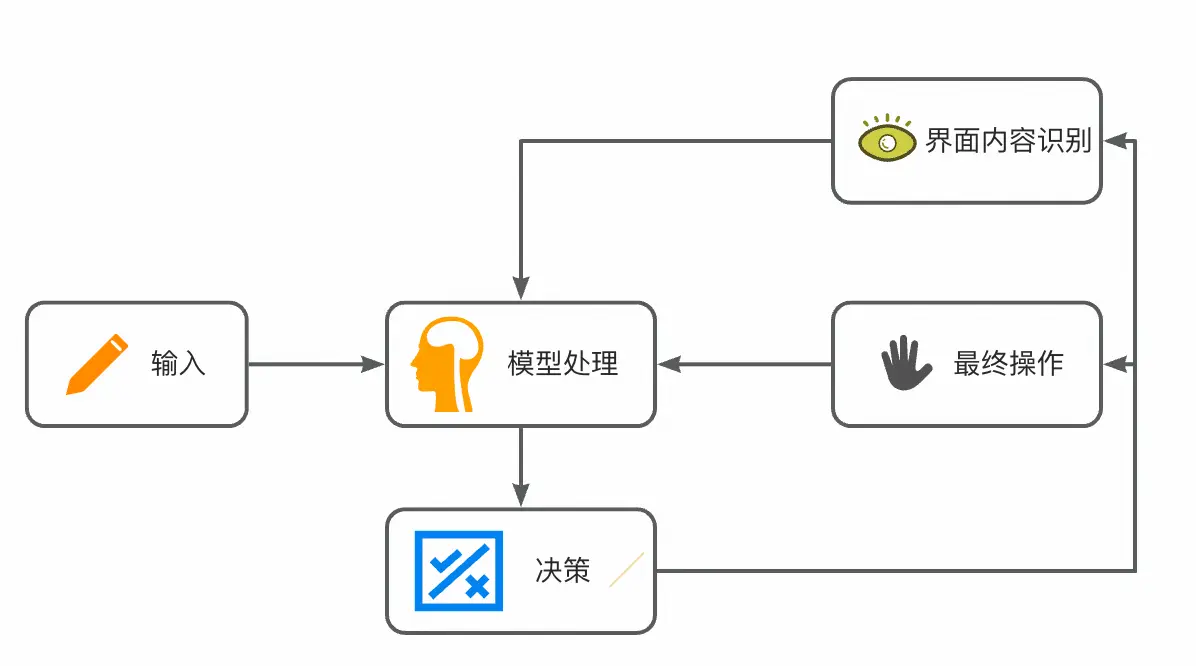
借着 AutoGLM 这个产品逐步分析一下
输入
LUI 作为输入端,目前来看无论 computer use 还是 phone use 基本上都是文本+语音的模式了,这个没什么可聊的。
模型处理
其实这部分接收三种类型的输入:
- 模型处理不光需要理解用户输入,还需要输出指定的工作流
- 根据界面内容识别,目前所处的阶段以及分析页面可操作部分
- 操作之后的内容识别,用来佐证操作是否正确,以进行下一步流程
我理解这部分的模型不只是大语言模型,也包括了一系列类似 MOE 的专家模型,针对不同的 APP 内容做专属的微调。
这也是目前只支持这 8 个 APP 的部分原因。

决策
这一部分决定了会在这 8 个 APP 中启用哪个 agent,一个 agent 代表一个 APP,目前只支持单个 agent 的操作,但是后续绝对会支持跨 APP 的 muilt-agent。
每一个 agent 中又包含了 tools 的使用,例如留言、查找等。
大脑作为统一中枢,根据决策去调用和共享信息。
同时决策也会根据大脑的工作流,一步步的引导操作和视觉识别。
界面内容识别
巧的是在 AutoGLM 推出不久,微软就开源了 OmniParser 作为界面内容识别的能力。这一块才是最重点的内容,真正做到非标准流程的标准!
最终操作
这块最简单 ui automator 等类似的软件都实现过,不过目前是结合界面内容识别来实现点击、拖拽等操作。
附:AutoGLM 内部使用手册: https://zhipu-ai.feishu.cn/wiki/Xxn8wPVdKiZQ2ukGdrqcRsHjnFg